
註:筆者居住於韓國,部分內容包含韓國特有的背景。
先來聽聽我們要做的音訊(日語)
1. TTS?
Text-To-Speech,顧名思義,是把文字轉換成語音資料的軟體。
只要做好一次,就可以在大量自動化情境中使用,不必擔心呼叫次數,所以我的目標是親手做一個。
既然要做,讓我熟悉的角色來說話不是更有趣嗎?所以我打算用自訂資料來微調模型,親手做一個 TTS。
其中,我們會使用 Bert-Vits2 這個模型來訓練。順帶一提,它支援中文、英文、日文。
如果你對角色的聲音不感興趣,只想要一個標準的韓文聲音,那麼建議你去看看 Melotts 與其預訓練模型。
最後再補充一句,做完模型之後請不要進行模型分發等行為,強烈建議只用於個人研究/興趣用途。
需要的東西是:一台帶 GPU 的 Ubuntu 伺服器,以及毅力(……)。
2. 工作流程
訓練至少需要 20 分鐘到 1 小時乾淨的語音資料。
如果能自己錄當然最好,但要用中文/日文/英文連續講 20 分鐘到 1 小時並不容易。
因此,我們打算使用動畫來製作訓練素材。
想法如下:
- 字幕中有字幕的開始時間、結束時間和文字資料。
- 在動畫中按字幕時長切出對應的音訊,然後把字幕文字作為該音訊的 Label。
整體流程如下:
- 找一部喜歡的動畫,以及它的原語字幕。
- 載入字幕資料和動畫資料,擷取台詞部分。
- 擷取台詞部分後,用機器學習移除背景音樂等。
- 自己一句一句聽台詞,刪除不是目標角色的資料。
- 這樣就會得到「目標角色」的「語音資料和標籤資料」。用這些資料訓練 Bert-VITS2。
- 用做好的 TTS 玩耍!
我會依照這個流程簡潔地說明一下。
3-1. 利用字幕檔擷取台詞部分
動畫和原語字幕請各位自行準備,這裡跳過。
進入我整理過的素材倉庫 Github 。
git clone 之後安裝相依套件,在 extract_wav_1.py 裡填入影片名與字幕檔名後執行。
這樣 data 資料夾內就會自動產生 1~xxx.wav 檔案。
3-2. 用 UVR (ULTIMATE VOCAL REMOVER) 移除背景音樂
進入 UVR 首頁 ,下載並執行。
接著請依下面的設定進行配置:
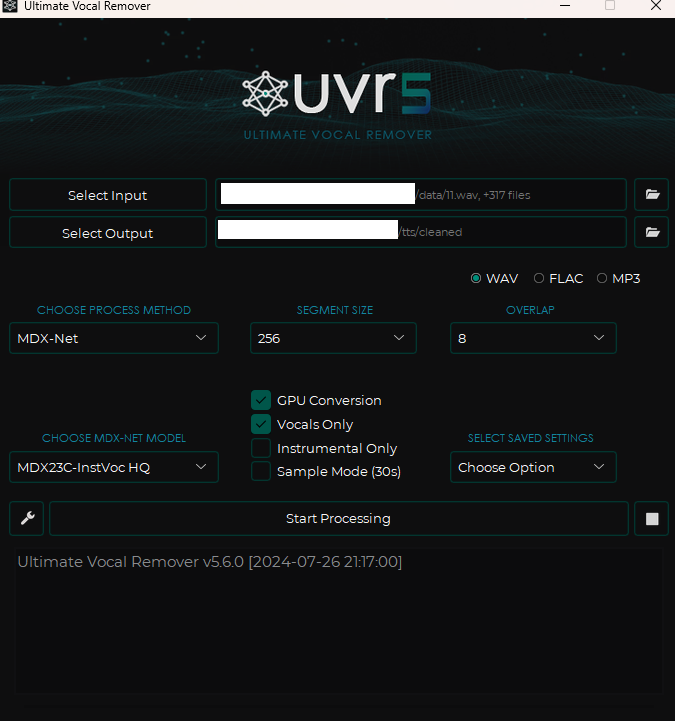
- input 處放入剛才產生的全部 wav 檔。
- output 處新建一個叫 cleaned 的資料夾。
- Choose MDX-NET Models 處,先 Download New Model -> MDX-Net 下載 MDX23C-InstVoc HQ 模型,然後選擇它。
- 開啟 GPU Conversion、Vocals Only 選項後執行。
3-3. 手動移除低品質音訊與其他角色的台詞
進入 cleaned 資料夾,移除低品質音訊(混入腳步聲、音效或聲音重疊的情況),以及其他角色的台詞。(直接刪除檔案)
3-4. 製作標籤資料
執行 change_name_2.py 修改 cleaned 資料夾中的檔名,
再執行 make_list_3.py 產生 esd.list 檔案。
3-5. 確認收集到的資料長度
執行 calculate_length.py,確認一共收集到多少分多少秒的資料。
3-6. 重複
如果資料還不夠,請重複前面的步驟,直到資料足夠。
在另一個目錄裡用角色名建一個資料夾,按下面的方式排列:
角色名/
ㄴesd.list
ㄴraw/
ㄴf6df34d9-01c4-4db9-97e9-a35795a5f64b.wav
ㄴ18bcc2c6-3e23-427c-a04a-9414b6f0b85e.wav
...esd.list 用文字編輯器打開,不斷追加內容; raw 資料夾則把 cleaned 中的 wav 檔貼進去即可。
不斷重複,讓總檔案長度達到 20 分鐘到 1 小時。
3-7. 訓練資料
把資料拷貝到 Ubuntu 伺服器。
如果 Ubuntu 上還沒有安裝 CUDA,請搜尋「Ubuntu CUDA 安裝」並安裝 CUDA。
Clone Bert-Vits2
倉庫,建立虛擬環境
後,執行 pip install -r requirements.txt 安裝相依套件。
接著執行 python webui_preprocess.py。
之後連到對應的 Gradio 環境,把各個檔案分別下載下來放到對應位置。

中文 RoBERTa -> 把 flax_model.msgpack、pytorch_model.bin、tf_model.h5 下載到 BERT_VITS2/bert/chinese-roberta-wwm-ext-large 資料夾。
其他的也一樣,把容量較大的檔案下載下來放進去。
日文 DeBERTa -> Bert-VITS2/bert/deberta-v2-large-japanese-char-wwm 資料夾
英文 DeBERTa -> Bert-VITS2/bert/deberta-v3-large 資料夾
WaveLM -> Bert-VITS2/slm/wavlm-base-plus 資料夾
接著新建 Bert-VITS2/data/{角色名} 資料夾,把訓練資料搬過去。
Bert-VITS2/
ㄴdata/
ㄴElaina/
ㄴesd.list
ㄴtrain.list
ㄴval.list
ㄴraw/
ㄴf6df34d9-01c4-4db9-97e9-a35795a5f64b.wav
ㄴ18bcc2c6-3e23-427c-a04a-9414b6f0b85e.wav
...此時,esd.list 是剛才做好的檔案原樣; val.list 是從 esd.list 最後 5% 左右複製貼上; train.list 則是 esd.list 中除掉 val.list 內容剩下的部分複製貼上。
範例:
esd.list
f6df34d9-01c4-4db9-97e9-a35795a5f64b.wav|Elaina|JP|ありがとう
b234c567-d890-1234-e567-890f123g4567.wav|Elaina|JP|おはよう
c345d678-e901-2345-f678-901g234h5678.wav|Elaina|JP|すみません
d456e789-f012-3456-g789-012h345i6789.wav|Elaina|JP|さようなら
e567f890-0123-4567-h890-123i456j7890.wav|Elaina|JP|元気ですか?train.list
f6df34d9-01c4-4db9-97e9-a35795a5f64b.wav|Elaina|JP|ありがとう
b234c567-d890-1234-e567-890f123g4567.wav|Elaina|JP|おはよう
c345d678-e901-2345-f678-901g234h5678.wav|Elaina|JP|すみません
d456e789-f012-3456-g789-012h345i6789.wav|Elaina|JP|さようならval.list
e567f890-0123-4567-h890-123i456j7890.wav|Elaina|JP|元気ですか?做到這裡,回到剛才的 Gradio,依下面的方式設定:
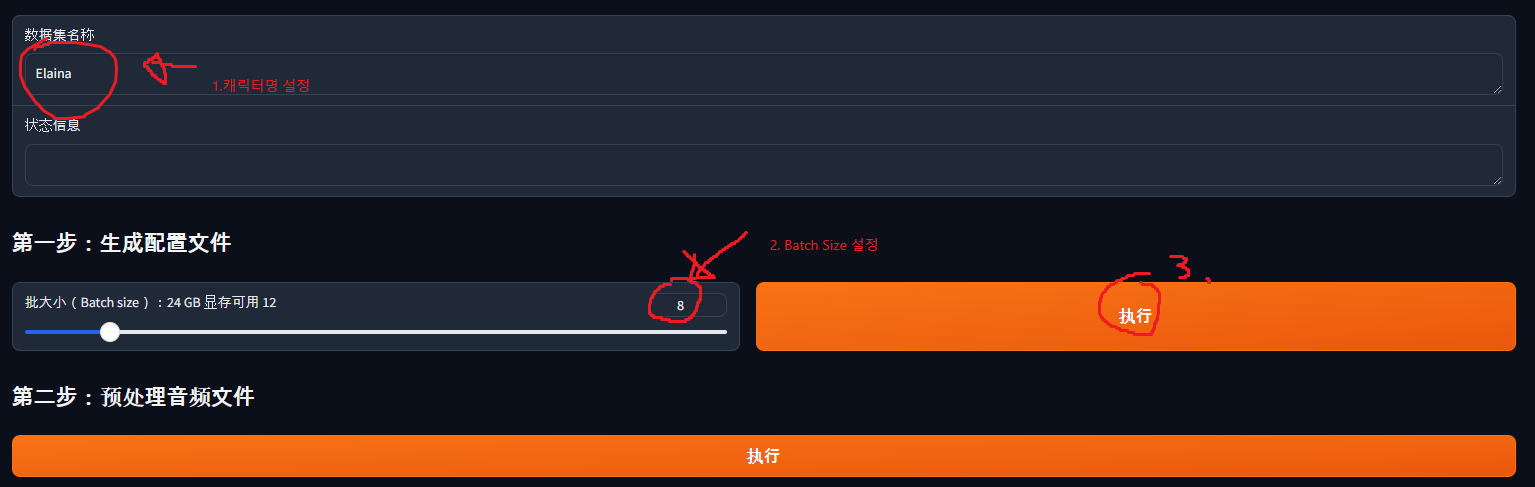
- 輸入角色名(我這裡是 Elaina)。
- 選擇 batch size。batch size 越大訓練越快,但太大就裝不進 GPU 顯存。我用的是 3090,所以設成 12,建議先用大值試試看,不行再降。
- 全部設定完後按按鈕。
按下按鈕後會產生 Bert-VITS2/config.yml 檔案。 修改這個檔案:
- 第 7 行的 “Data/” 部分改成 “data/{角色名}"。(我這裡是 data/Elaina)
- 第 20 行的 in_dir 從 “audios/raw” 改成 “raw”。
- 第 22 行的 out_dir 從 “audios/wavs” 改成 “wavs”。
- 第 29 行的 transcription_path 改成 “filelists/esd.list”。
之後回到 Gradio,依序點擊 第二步:预处理音频文件、第三步:预处理标签文件、第四步:生成 BERT 特征文件。
接著下載預訓練模型。
進入下面的連結 ,下載 DUR_0.pth、D_0.pth、G_0.pth、WD_0.pth,貼到 data/{角色名}/models 資料夾。
接著把 config.yml 第 90 行的 config_path 改成 “configs/config.json”(train_ms 部分)。
之後在 Bert-VITS2 資料夾下執行 torchrun --nproc_per_node=1 train_ms.py,訓練就會開始!
3-8. 輸出語音
訓練進行的過程中,需要確認語音是否能正常輸出。
打開 data/{角色名}/models 資料夾,會看到隨著訓練進度產生多個檔案,例如 G_1000.pth 這種形式。
G_xxxx.pth 檔案就是用來產生聲音的檔案。 確認該資料夾後,把 config.yml 第 105 行(webui 部分)的 model 改成 “model/G_xxxx.pth”。(這裡 xxxx 是目前目錄中存在的模型編號)
接著在 Bert-VITS2 資料夾中執行 python webui.py,就會啟動一個 Gradio,可以在該 Gradio 中測試 TTS。
順帶一提,如果想用這些資料另外架一個伺服器,可以參考 hiyoriUI.py!它提供了基於 fastAPI 的伺服器。
結語
到這裡為止,簡?單地說明了一下如何製作 TTS。
中間漏掉不少細節,是因為已經有類似的文章了,我只重點寫了那篇文章中我自己覺得困惑的部分。
Chapter 4. Bert-VITS2 訓練前準備與開始訓練
本文中遺漏的部分,搭配上面這篇一起看會更好理解。
我自己已經把 TTS 移植到另一台正在跑的機器學習伺服器上,用得很順手。
如果有什麼不順利的地方歡迎留言,也祝各位做出有趣的 TTS!
Comments