註:筆者居住於韓國,部分內容包含韓國特有的背景。
來聊聊我做了這樣一個服務的故事!
2024.06.30 補充:那時 ChatGPT 還沒出現,這種聊天機器人服務並不常見!
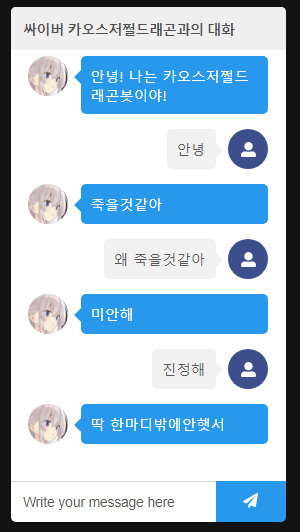
啊啊啊啊到底發生什麼事了!!
1. 為什麼會開發這個?
原本寫了挺長一段,但別人的 TMI 估計不太有趣,所以簡單寫。不過即便縮短了,依然挺長的!
我業餘在讀利用深度學習的自然語言處理入門 ,看到使用 BERT 句向量的韓文聊天機器人 那部分時,突然冒出一個想法:訓練資料用推文應該也行吧?
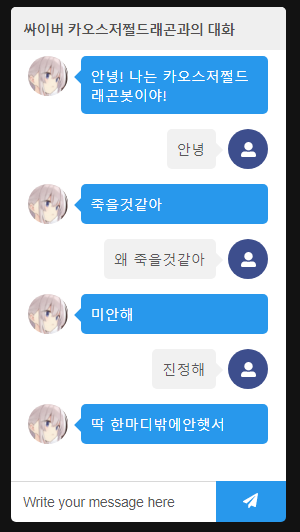
咦,這個……用 Twitter 的提及應該也能做出類似的吧?
是不是可以做成這樣?
問題在於訓練資料的數量,Twitter API 在請求最近推文時,最多只提供 3200 筆推文資料。
保守估計其中一半是公開推文(朝著虛空發的推文),那大約有 1600 筆推文可作為訓練資料。如各位所知,在機器學習裡 1600 筆訓練資料量太小,很難做出有意義的聊天機器人。
但只要看起來有趣,難道不值得先試一下嗎?
所以我決定動手做做看。 啊……那時還不知道,自己竟然會為了把大約 200 行的 Colab 程式碼改造成一個服務而燒掉一個多月……
2. Serverless ML?
產生機器學習轉換資料的極其簡單的結構如下。

也就是說,單台伺服器一次只處理一個,每個人大約要 15 分鐘!
那麼大概一小時能處理 4 個人! 100 個人就是 25 小時, 1000 個人來就是 250 小時……
今天註冊服務的話,10 天後才會完成!
而且這還是不算聊天機器人問答部分的數字!
啊……這有點……得想點別的辦法……
啊!想想用 Serverless 架構應該不錯。 有些朋友可能不太了解 Serverless 的概念,我用圖簡單說明一下。
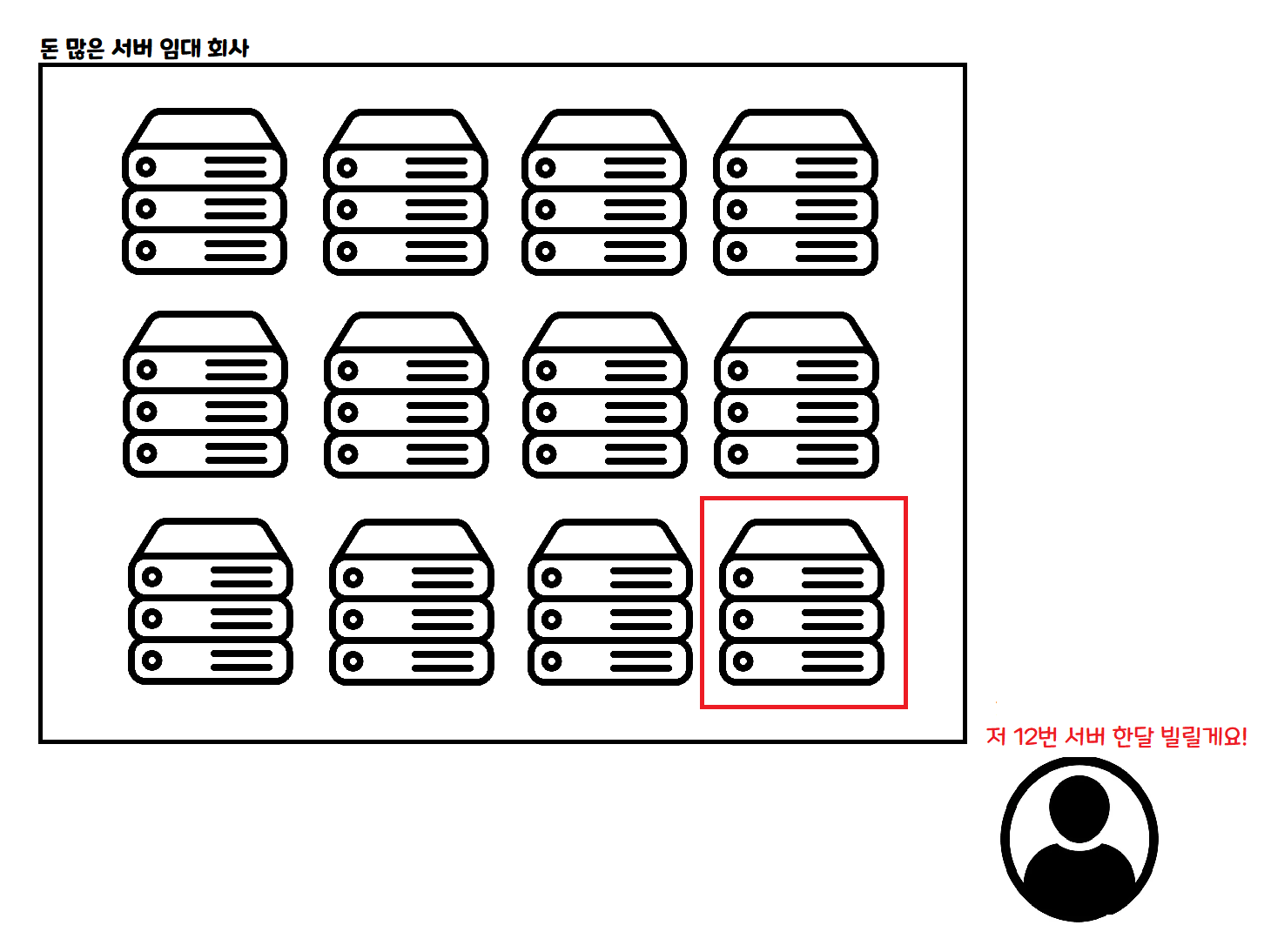
這是傳統的雲端使用方式。按一個月、一週、一天等固定期限租用一台電腦,依照租用時間付費。VPS 這個東西就是類似的概念!
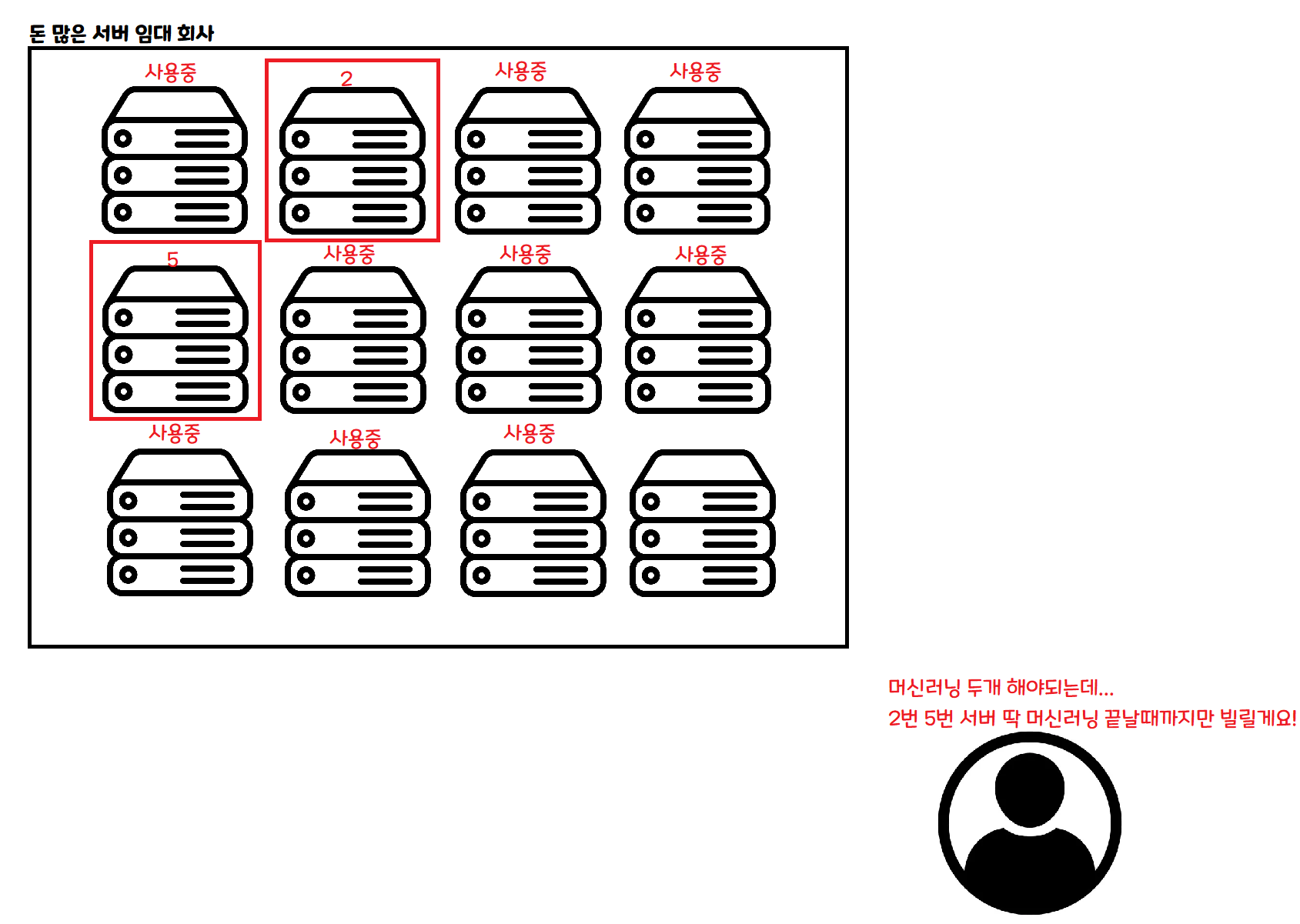
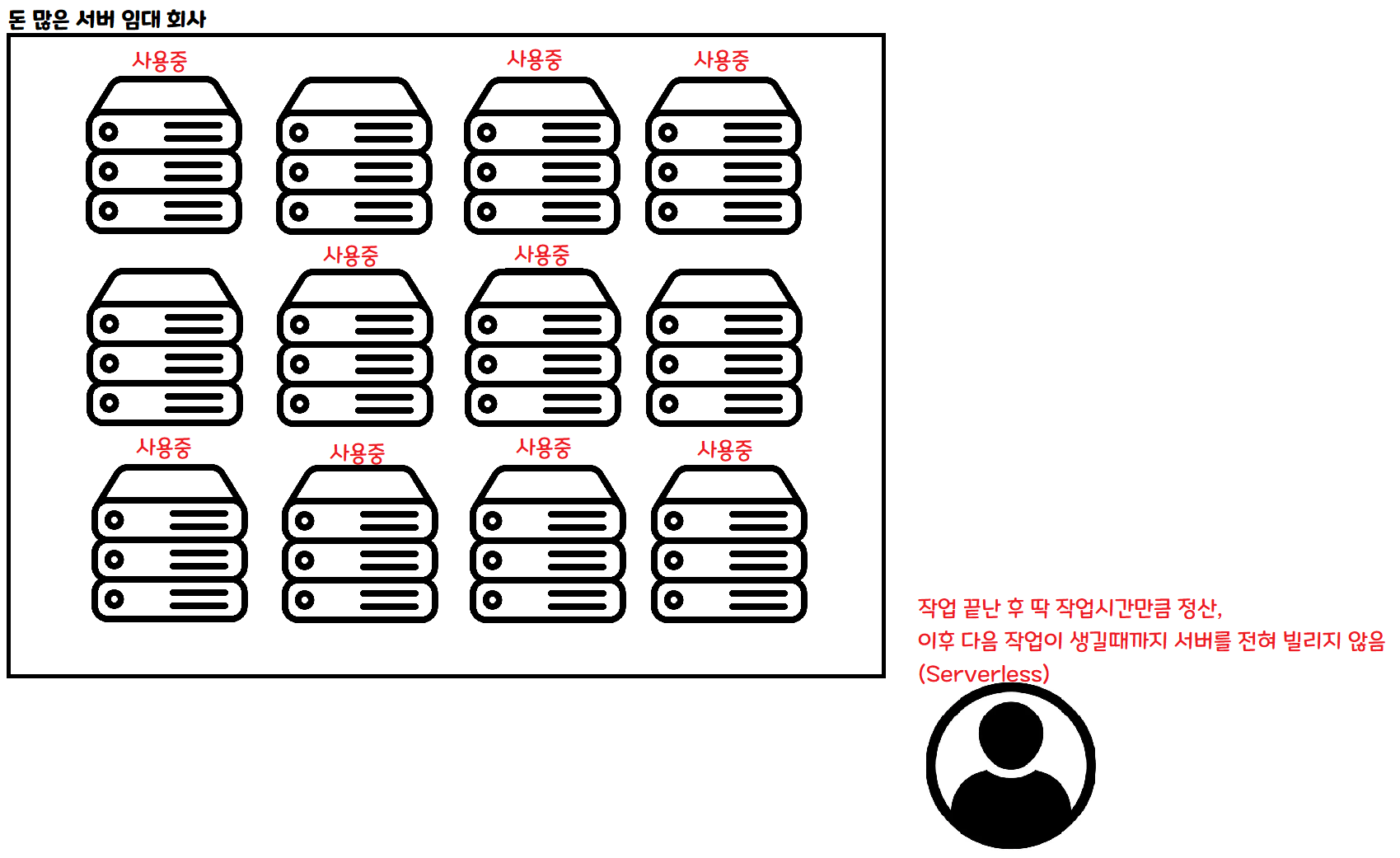
這是 Serverless 的方式。要做某項工作時按需申請,就只在那項工作完成之前借用一段時間。
如果同時來 100 個人,可以同時租用 100 台伺服器並行處理。 如果一個人都沒來,那段時間就不必租用任何伺服器。
採用這種架構的話,理論上無論來多少人,處理資料的速度都跟只來一個人時一樣! 當然實際上還是會有別的問題。
啊!問題解決了!就這麼幹一波吧!
3. 現實沒那麼輕鬆
我以為大致這樣做就行了,沒想到……
啊……。 是不是大家也突然覺得頭疼? 把它非常非常簡單地總結一下就是下面這樣。
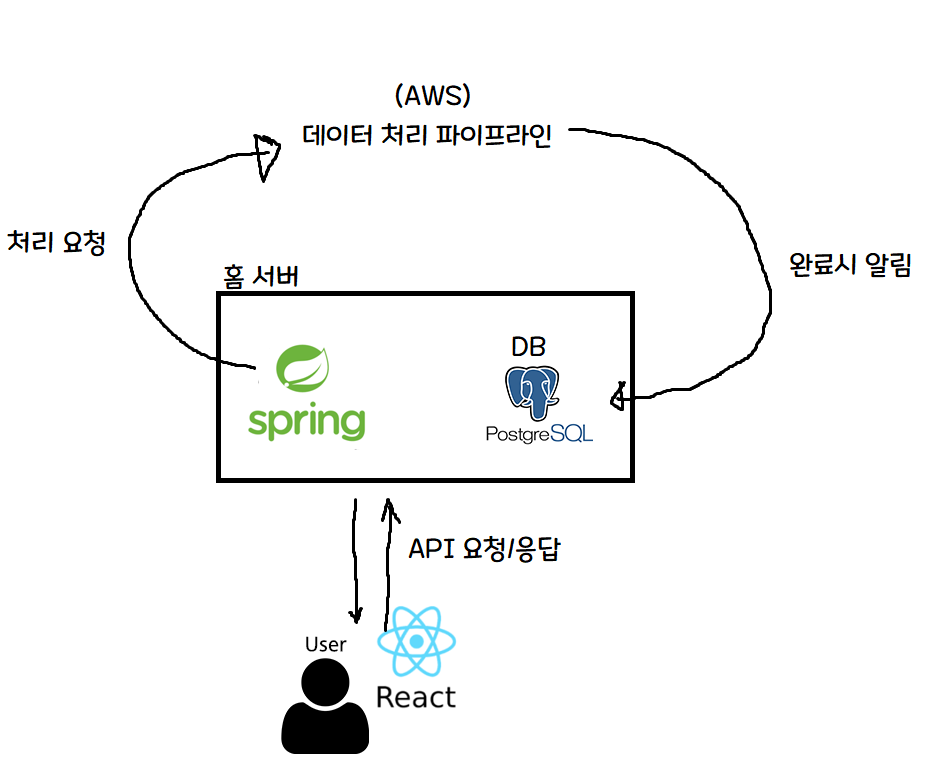
啊,這樣就好懂多了!
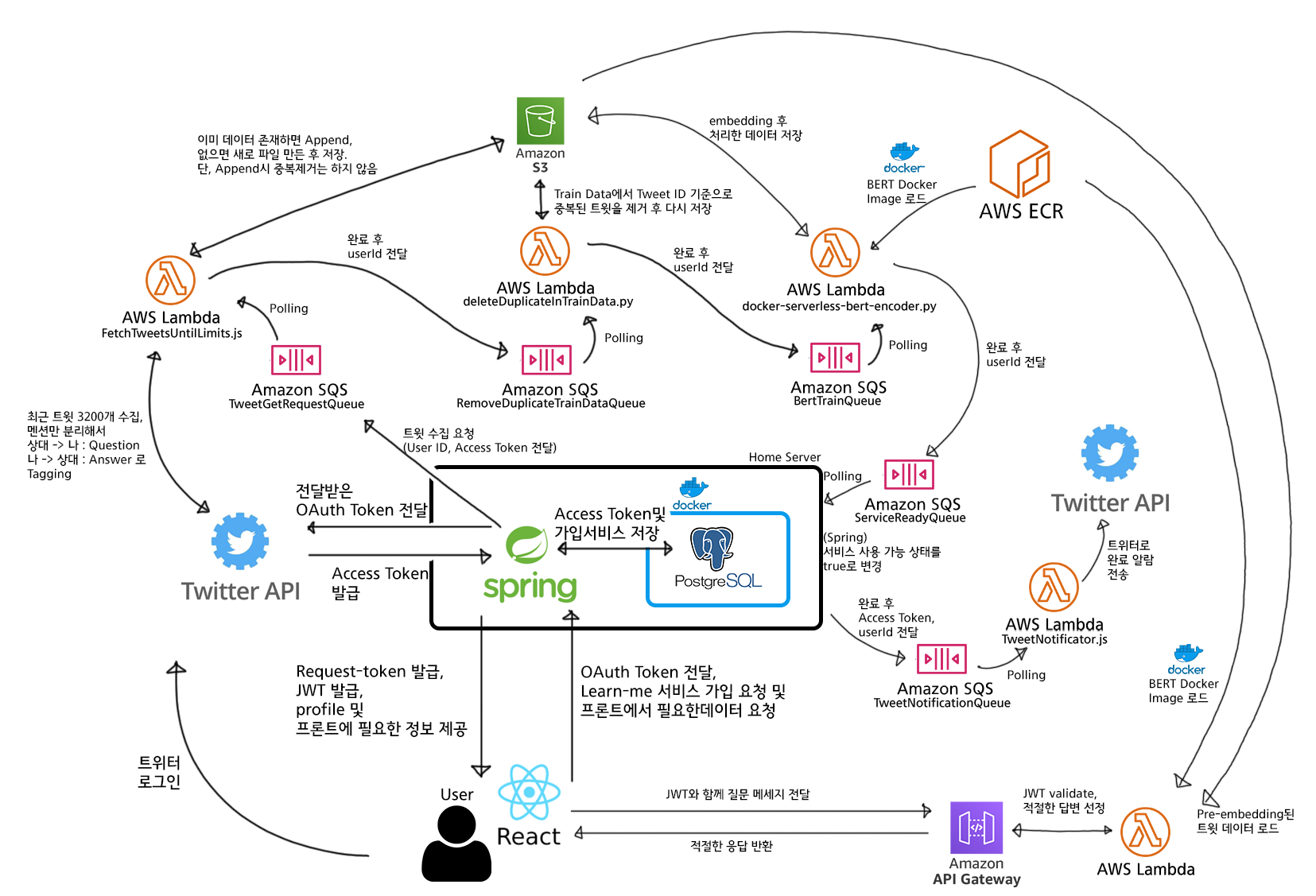
核心部分如下。
- 為節省伺服器費用,註冊/認證 token 簽發等只由家用伺服器上的 Spring 伺服器處理。
- 重負載的機器學習運算發送請求到雲端(AWS),利用 AWS 的伺服器資源處理。
- AWS 處理完成後通知家用伺服器,並把處理完成的事實寫入 DB。
我個人有家用伺服器,所以抱著用家用伺服器處理輕量運算以減少租用費用、把重運算交給雲端服務(AWS)的方式同時拿下性價比和效能的夢想與希望,把這個服務做了出來!
4. 上線 — 副標題:瓶頸往往出現在意想不到的地方
抱歉…… 不是,那個…… 計畫本來明明很完美……
我當然以為這個專案的瓶頸會出現在機器學習部分,並以此為前提搭建了整個系統,結果意外地……並非如此。
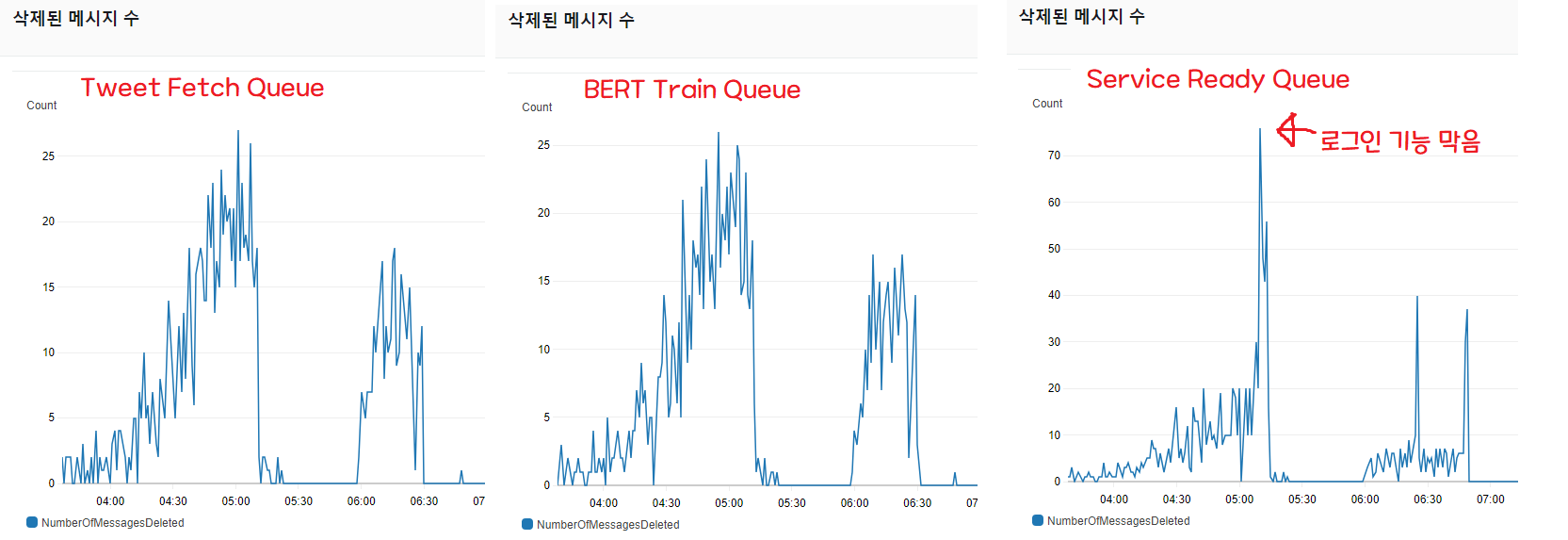
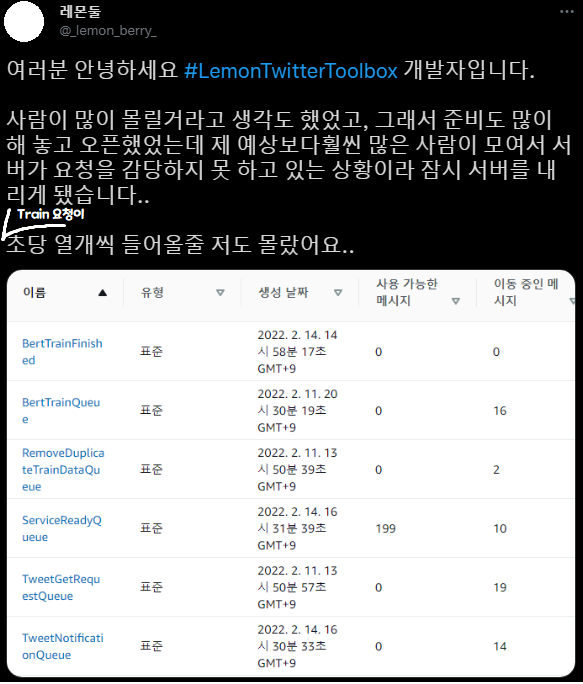
已刪除訊息數量是衡量處理量的指標。 當請求以訊息形式進入時,它代表一分鐘內處理了多少筆請求並刪除了訊息。
如各位所見,抓取 3200 筆推文的腳本和處理 BERT 機器學習的佇列動作類似,把請求都消化掉了(1 號和 2 號曲線)。
但是當所有流水線作業成功後,向 Spring 通知處理完成、並把 DB 中「可用」欄位改為 true 的佇列(3 號),處理量卻跟不上。
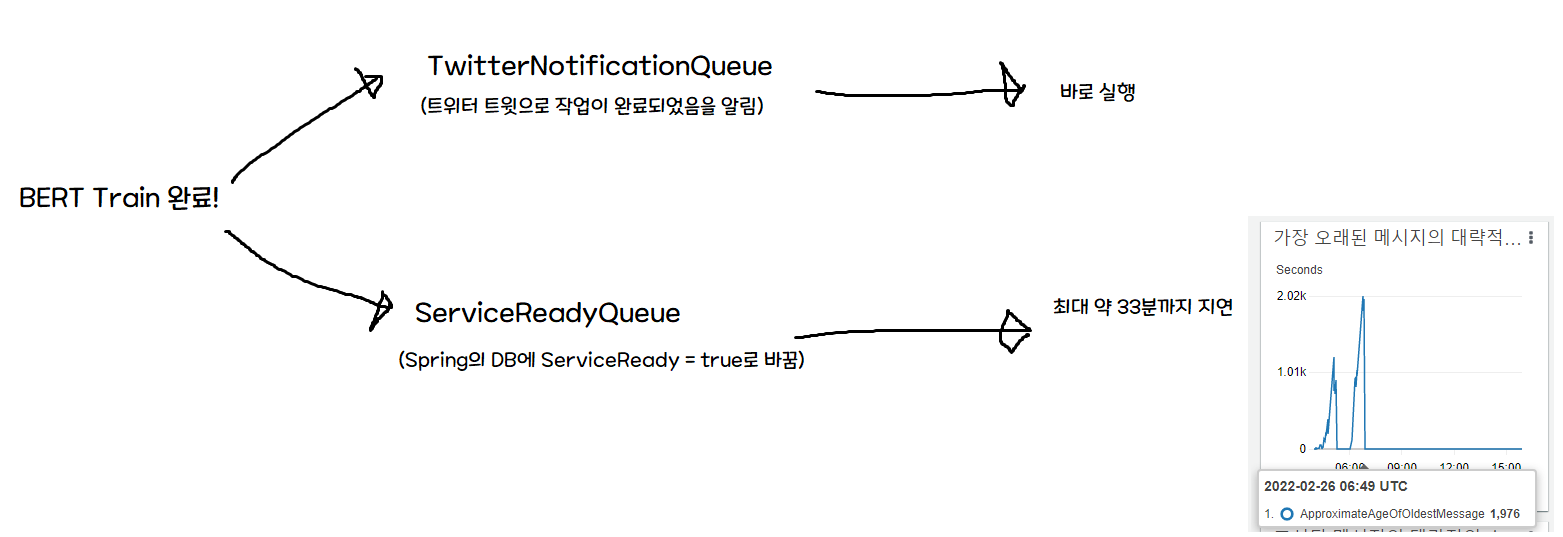
問題在於,初期架構假設 ServiceReadyQueue 會立刻被處理掉。
因此訓練完成時,Twitter 通知(Serverless)和 Spring 通知是同時發出的,但 Twitter 通知會立即送達,而 DB 寫入存在延遲。 也就是說,收到通知後過來的使用者最多會有 33 分鐘看到「無法使用!」的畫面。
老實說,這裡我糾結了挺久。
啊……這是一輩子都遇不到的流量……要不要把登入關掉……得關掉吧……? 都積壓 30 分鐘了……?
Spring 每分鐘消費 10 條訊息,所以只要每 6 秒註冊一個使用者以下的速率,瓶頸就會自動消解。但監控顯示完全沒有減少的趨勢,於是我決定先把登入關掉。
判斷標準很明確:處理變慢沒關係,但顯示已處理卻無法使用是非常大的缺陷。
於是我趕緊改了 React 專案,把登入按鈕和服務註冊按鈕拿掉,並緊急把流水線改成下面這樣。

這樣改之後,處理速度沒有變化,但可以避免收到通知卻無法使用這種致命情況。
之後等了一小段時間,讓 DB 寫入完成(讓積壓的工作跑完),再把登入/註冊按鈕恢復回來。
之後服務就如預期一樣正常運作了。雖然瓶頸本身沒解決,但至少避免了收到完成通知後過來卻幾十分鐘無法使用服務這種致命錯誤。
接著我一邊監控一邊分析原因,發現訊息處理量被固定在最多 10 條,於是去查相關資料,在 spring-cloud-aws 的 issue 中找到了這個 issue。簡而言之,就是一次只能處理 10 條訊息,且不是非同步而是同步執行的問題。
再看目前仍然 open 的另一個 issue ,這個問題需要大規模重構,預計在 3.0.0 修復。結論上……
啊……那熱修復就難了……
總之,瓶頸本身沒辦法簡單解決,要解決的話,要麼把 Spring 做的工作本身改寫為 Serverless 架構,要麼對函式庫依賴動大手術(……)。不管怎樣,剛上線當天不該折騰這個,所以決定先繼續監控。
啊!
這次輪到另一個佇列開始堆訊息了。就是抓取 3200 筆推文的那個佇列。 我立刻進入監控,發現處理該佇列的 Lambda 函式錯誤率上漲到了 100%。
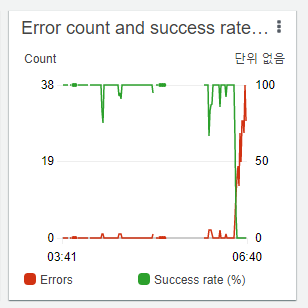
這一看就是 API 限流嘛!
進入 CloudWatch,打開該 Lambda Function 的日誌,果然不出所料。
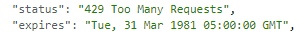
果然是 API 限流!
雖然不知道具體是哪種限流
(Twitter 有使用者限流、應用程式限流、15 分鐘限流、每日限流、每月限流等各種各樣的限制……)
但顯然得把服務註冊按鈕拿掉了(……)。
拿掉服務註冊按鈕,並在 Twitter 上發了相關公告之後,暴風雨般的 3 個小時就這麼過去了。
吃了每日限流之後我已經沒什麼可做的了(……),於是決定給服務做個驗屍留個紀錄,所以現在正在寫這篇。
5. 結論及後記
啊……我完全沒想到 SQS -> Spring 這段會成為瓶頸, 也好像是第一次體驗到那種一直夢寐以求的、突然湧入大量流量但伺服器扛不住時的恐慌狀態。
尤其是因為整個服務都是我自己做的(……),故障點找得倒是挺快,但最難的是思考如何在線上服務運作中的狀態下進行修復?副作用會怎樣?等等。
特別是中間那種**「服務出現嚴重故障(收到通知但無法執行)」**的情況,得在線上伺服器上快速修復,又不知道倉促寫出的程式碼會帶來什麼副作用,還要趕緊熱修復,這在心理上壓力很大,應該是最讓我緊張的時刻。
老實說最大的感受是
啊,原來這就是為什麼大家一直說自動化測試自動化測試…… 如果有大量的測試,就算遇到類似情況,也能更安心地修改。
我當時就是這麼想的。
另外,雖然不是有意為之,但我從 AWS 上得到了很大幫助(?)
- 透過使用基於佇列的架構,我能很快知道在哪個環節出現瓶頸、在哪裡發生錯誤。 如果沒有用 SQS,找瓶頸會花更多時間,但多虧了基於佇列的架構,我能很輕鬆地找到瓶頸所在。
- 我意識到 CloudWatch 日誌非常非常方便、非常重要。 本來是想把監控系統也搭好再發布,但抱著先發出來看看反應再說(?)的天真想法,就直接上線了。 但果然出了問題,開發時習慣性留下的狀態變化和 Exception 輸出等,對錯誤處理起到了很大幫助。 即使不用 AWS,也要好好打日誌、學好怎麼看日誌……

- 一定要設定 DLQ。 Poller(服務處理者)處理 N 次以上仍因 Exception 等無法處理的訊息,可以收集到 DLQ(Dead Letter Queue)中,利用 DLQ 之後可以透過 DLQ 重新驅動(redrive)功能把未處理的訊息送回原佇列。 也就是說,如果有請求因某些原因發生錯誤而未能處理,就會進入 DLQ,之後可以利用 DLQ 重新驅動從中斷點重新開始處理!
總之……雖然挺辛苦,但好歹算是跌跌撞撞地挺過來了,真是太好了!
如果我有理解錯的地方或者可以改進的地方,歡迎隨時留言!非常感謝您讀完這篇長文!
Comments