
注:作者居住在韩国,部分内容包含韩国特有的背景。
最近,我养成了在闲暇时读论文的习惯。 其中,我在 arxiv 上读到一篇有趣的论文,所以想整理并分享一下。
论文标题是 ChatGPT is a Knowledgeable but Inexperienced Solver: An Investigation of Commonsense Problem in Large Language Models (Arxiv Link
)。
主题是:大规模语言模型(ChatGPT)能很好地解决常识问题吗? 这是一个相当有趣的话题,所以我想一边学习一边分享,整理一下读到的内容。
我从未读过论文,本科的记忆也已模糊,所以提前说明可能会有错误!(如有错误请告诉我,嘿嘿)
1. 摘要
论文提出了以下问题:
- GPT 能否有效地回答关于常识的问题?
- GPT 是否对常识了解得很好?
- GPT 能否很好地区分回答某个特定问题所需的常识与不需要的常识?
- GPT 能否有效地利用给定的常识来回答问题?
简要回答如下:
- 可以有效地回答,但在社会规范、因果关系、时间相关的特定领域回答得不太好。
- 大部分常识都掌握得很好。
- 不能很好地区分回答问题所密切相关(必要)的常识与不相关的常识。
- 即使在上下文中输入额外的常识,也无法很好地使用。
2. 常识的分类
研究人员将常识分为 8 个类别。 分别如下:
1. 一般(General)常识(广泛共享的常识)
- 太阳从东方升起
2. 物理(Physical)常识(关于物理世界的知识)
- 玻璃杯掉下来会碎。水向下流。
3. 社会(Social)常识(关于社会规范的知识)
- 受到帮助应该说"谢谢"。
4. 科学(Science)常识(科学概念的原理/知识)
- 重力将所有物体拉向地球中心。
5. 因果关系(Event)常识(关于因果关系和顺序的知识)
- 打翻水杯 -> 水洒出来
6. 与数字相关的(Numerical)常识(与数字相关的常识)
- 人有 2 只手和 10 根手指
7. 典型的(Prototypical)常识(关于概念的知识)
- 燕子是鸟的一种,有翅膀
8. 与时间相关的(Temporal)常识
- 海外旅行比散步花的时间更长。
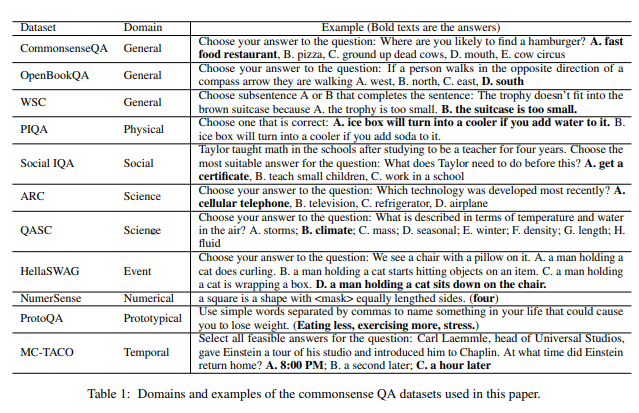
然后,研究人员为每个类别准备了 11 个与常识相关的数据集。
从左到右是数据集名称 / 类别 / 示例问题。
3. ChatGPT 能否有效地回答常识问题?
研究人员从上述每个数据集中各抽取 100 个问题,分别向 GPT3、GPT3.5、ChatGPT 模型提问。
下面是 GPT3、GPT3.5、ChatGPT 对每个问题的正确率。
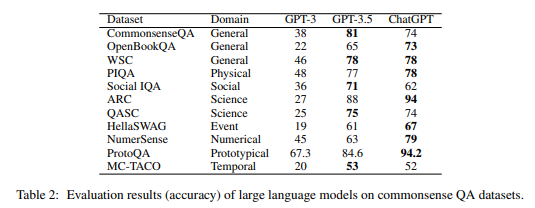
值得注意的几点:
- 整体回答得不错
- 科学(Science)领域以约 94% 的正确率最高。
- 社会规范(Social)、因果关系(Event)、时间(Temporal)的正确率较低(低于 70%)
- 整体上,相比 GPT 3.5 模型,调优模型 ChatGPT 的精度更高
- 在某些问题上 GPT 3.5 的正确率看起来更高,但这更多是 ChatGPT 回答"仅凭给定数据无法得出答案"造成的错觉。
4. ChatGPT 能否很好地区分回答问题所需的常识和不需要的常识?
研究人员从上述问题数据集中,每个数据集再抽取了 20 个。
然后,向 GPT 询问"回答这个问题需要什么知识",并基于人类的回答计算 Precision(精确率)、Recall(召回率)、F1 Score。

Precision? Recall? 出现了难懂的词,所以先整理一下再继续。
Precision:GPT 给出的答案的准确度
- GPT 的回答中正确的占多少 %?
- 例如 5 个回答中,3 个正确 2 个错误,那么 Precision 是 60%
Recall:全部正确答案中 GPT 找出的正确答案的数量
- 人预测的正确答案中,GPT 找出了多少个?
- 例如预测正确答案有 5 个,GPT 在 10 个回答中 4 个正确、6 个错误,那么 Recall 是 80%(4/5)
- 计算 Recall 时错误答案不重要!
F1 Score:Precision 和 Recall 的调和平均
- 只用 Precision 作为指标?:只需给出概率最高的答案仅一个即可
- 只用 Recall 作为指标?:写一万个答案,其中总有几个会蒙对
- 但我们想要的是"准确地"且"足够多地"回答的 AI 模型
- 因此对 Precision 和 Recall 取调和平均就能得到类似"准确度"的指标!
- 也就是说,F1 Score 高 == 回答得好!
讲了这些难懂的内容!结论上得到了如下结果。
- GPT 的 Precision 低但 Recall 高
- 在整个数据集上,Precision 是 55.88%,但 Recall 是 84.42%
- 也就是说,解决问题所需的知识几乎都能告诉你,但准确度并不高
- GPT 在科学领域表现相对较好(F1 74~76%),但在社会规范、时间领域表现尤其差(F1 低于 50%)
5. ChatGPT 在常识方面博学吗?
研究人员基于在第 3 节生成的所需知识手动制作了问题提示。然后,手动评估 GPT 生成的回答是否正确。

上面的问题是 ChatGPT 生成的错误答案的示例。
GPT 说 blowing into a trash bag and tying it with a rubber band may create a cushion-like surface, but it is unlikely to be durable or comfortable for prolonged use as an outdoor pillow(翻译:往垃圾袋里吹气并用橡皮筋绑起来可能形成像垫子一样的表面,但作为户外枕头长时间使用可能不耐用或不舒适),但据说用垃圾袋做枕头是常见做法,因此被判定为错误答案。
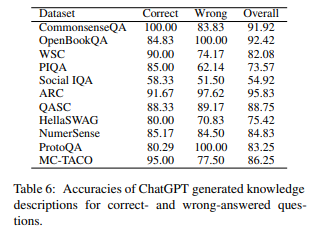
根据上面的结果表,研究人员得出了以下结果:
- GPT 是博学的,掌握了回答问题所需的大部分常识。
- 在整个数据集上平均准确度为 82.66%
- 在大部分数据集上准确度超过 70%。
- 但是,在社会规范领域准确度仅为 54.92%,性能较低。
- 但是,GPT 的回答中也包含可能引起误解或过度泛化、不需要的知识
- 全部回答的 26.25% 包含相关性低且可能引起误解的信息。
- 大约 15% 的解释过度泛化,不是回答问题所需的具体信息
6. ChatGPT 在响应时能否利用从对话上下文中添加的常识来回答?
为了确认 GPT 能否利用上下文中出现的常识进行回答,研究人员像第 4 节一样让 GPT 推断回答问题所需的常识,然后让其再次回答同一个问题,确认回答是否得到改善。

上面的示例展示了之前错误的答案在生成额外说明后仍然没有改变的例子。
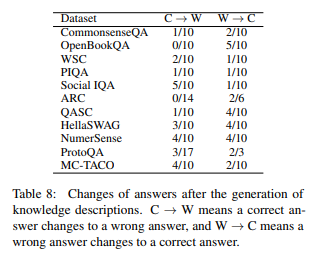
根据上面的结果表,研究人员得出了以下结果:
- GPT 仅靠将 GPT 生成的常识说明添加到对话上下文中,无法有效地用于回答。
- 当上下文中添加说明时,正确变错误的情况(C->W)和错误变正确的情况(W->C)都存在
- 在 Social IQA 数据集上,由于上下文中添加的常识有误,正确变错误的情况(5 个)反而比错误变正确的情况(1 个)更多。
- 研究人员推测,由于模型中已经生成了知识,仅仅生成额外信息没有太大效果。
甚至,即使在对话上下文中添加的不是"GPT 生成的常识",而是"用户直接添加正确的常识",正确率也无法达到 100%。
- 基于人工标注的 CoS-E、ECQA 数据集,将正确答案(Golden Knowledge)添加到对话上下文中。
- CoS-E 错误->正确增加了 4 个
- ECQA 错误->正确增加了 8 个,正确->错误增加了 1 个
- 研究人员推测 GPT 缺乏运用复杂推理(例如否定推理)等能力
- 否定推理示例
- Q:篮球破了一个洞但形状保持原样,错误的是?
- A:破了一个洞,B:在美国很受欢迎,C:充满空气
- CoS-E 数据集解释"有洞的物体里空气无法停留",但 GPT 仍然预测 A
- 否定推理示例
// TODO:继续写…
Comments