
注:作者居住在韩国,部分内容包含韩国特有的背景。
安装 Helm
- 参考文章:Installing Helm
依次输入以下命令安装 Helm。
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.sh
./get_helm.sh然后配置 kubeconfig 文件。
cp /etc/rancher/k3s/k3s.yaml ~/.kube/config
chmod 600 ~/.kube/config接着在 bashrc 的最底部添加下面这一行,再用 source ~/.bashrc 立即应用 Shell 设置。
export KUBECONFIG=~/.kube/configHelm 在 Kubernetes 中的角色类似于包管理器。
例如,假设我想以集群模式安装 Kafka。
如果我要手动把 Kafka 部署到 Kubernetes 上,就得拉取 Kafka 容器镜像、打开集群选项、设置内部网络连接……所有这些工作都得自己做。
再想象一下升级 Kafka 版本的场景。
要在自己写的 Kafka 集群 YAML 文件中提升容器镜像版本……如果集群安装时还用了其他资源,就要确认是否兼容……等等一系列复杂的工作正等着你。
但如果有人提前把这些工作做好了呢?
这就叫做 Helm Chart,我们只需要输入 helm install kafka,就能得到一个网络与集群设置都已配置好的 Kafka 集群。
不过如果大家都用同一个 Helm Chart,那么像我们这种(?)只想为了试验而启动一台 Kafka 容器的人,和需要数百台 Kafka 组成集群的大公司,就只能使用相同的设置了。
为了应对这种情况,Helm 和 Chart 提供了一个名为 Values.yaml 的额外配置文件。
也就是说,如果我只需要一台容器,那么仔细阅读 chart 的 values.yaml,并像 kafka.container-count : 1 这样设置,就能注入相应变量,从而灵活地以自己需要的配置使用 Helm Chart。(就像服务器的环境变量一样!)
安装 MetalLB
现在让我们用 Helm 来安装负载均衡器 MetalLB!
依次输入以下命令。除非另有说明,所有命令都在 Control Node 上输入。
helm repo add metallb https://metallb.github.io/metallb
helm upgrade --install metallb metallb/metallb --create-namespace --namespace metallb-system --wait然后创建一个名为 ip-address-pool.yaml 的文件,按下面的内容编写,并用 kubectl apply -f ip-address-pool.yaml 应用。
以下内容的意思是:将 192.168.0.200~192.168.0.250 之间的 IP 分配给负载均衡器等需要 IP 的服务。
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: ipaddresspool
namespace: metallb-system
spec:
addresses:
- 192.168.0.200-192.168.0.250
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: default
namespace: metallb-system
spec:
ipAddressPools:
- ipaddresspool至此,如果配置正确,使用 LoadBalancer 的服务就会被分配 IP。
输入 kubectl get svc -n kube-system,检查 traefik 的 EXTERNAL-IP 是否被分配了 192.168.0.xxx。
如果没有特别设置的话,多半会被分配到 192.168.0.200。
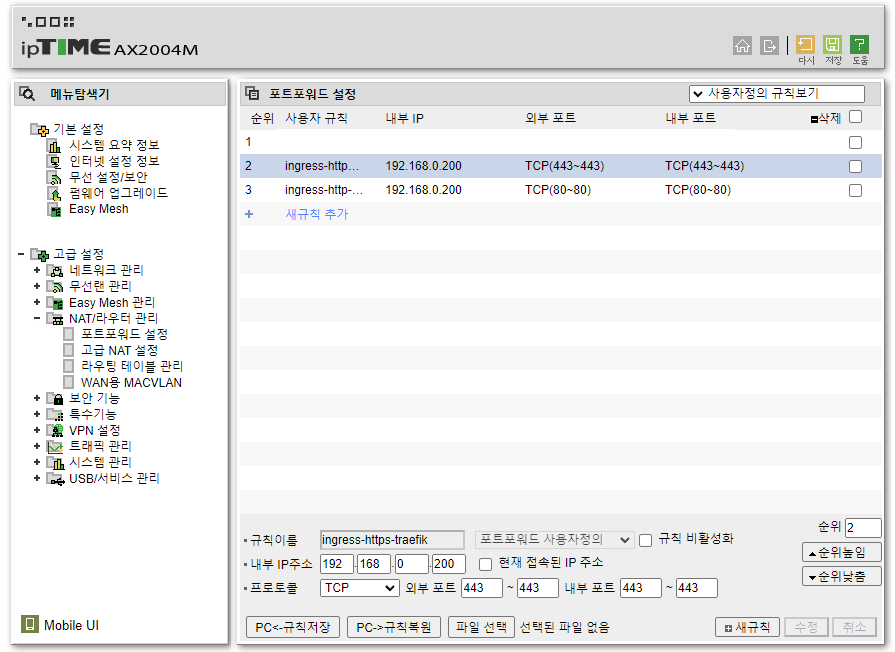
路由器端口转发设置
确认 Traefik 的 IP 后,我们先把(下次要做的事情中的)一项提前做好。
找到路由器的端口转发设置,把 80、443 端口转发到上面确认的 Traefik IP。
MetalLB 是怎么工作的?
MetalLB 可以以 ARP 模式和 BGP 模式两种方式运行,但我们使用的是 ARP 模式,所以来非常简单地(?) 看一下 ARP 模式的工作方式。
在看图之前,需要一点背景知识。
- MAC 地址是写死在硬件上的地址,从出厂起就存在,并且是唯一的。
- 路由器的端口转发,作用是当外部以特定端口发来请求时,将其转换为内部网络的特定 IP 后再发起请求。
- 例如,如上面设置的那样,把 80 端口、443 端口设置为 192.168.0.200,那么对于 http(80 端口)、https(443 端口),就会在内部网络中连接到拥有 192.168.0.200 的节点。
之后的网络请求流程如下。
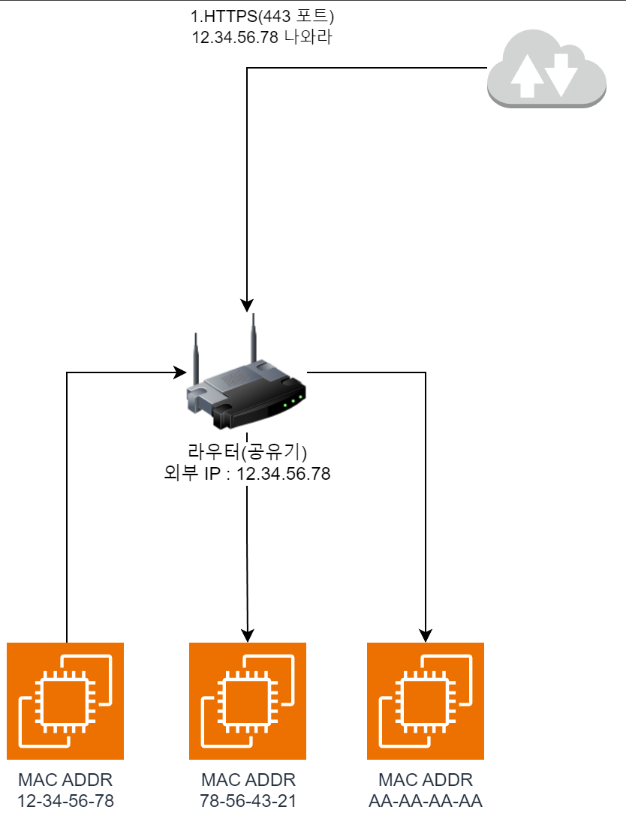
- 通过
https://访问服务器时,外部会请求443端口。
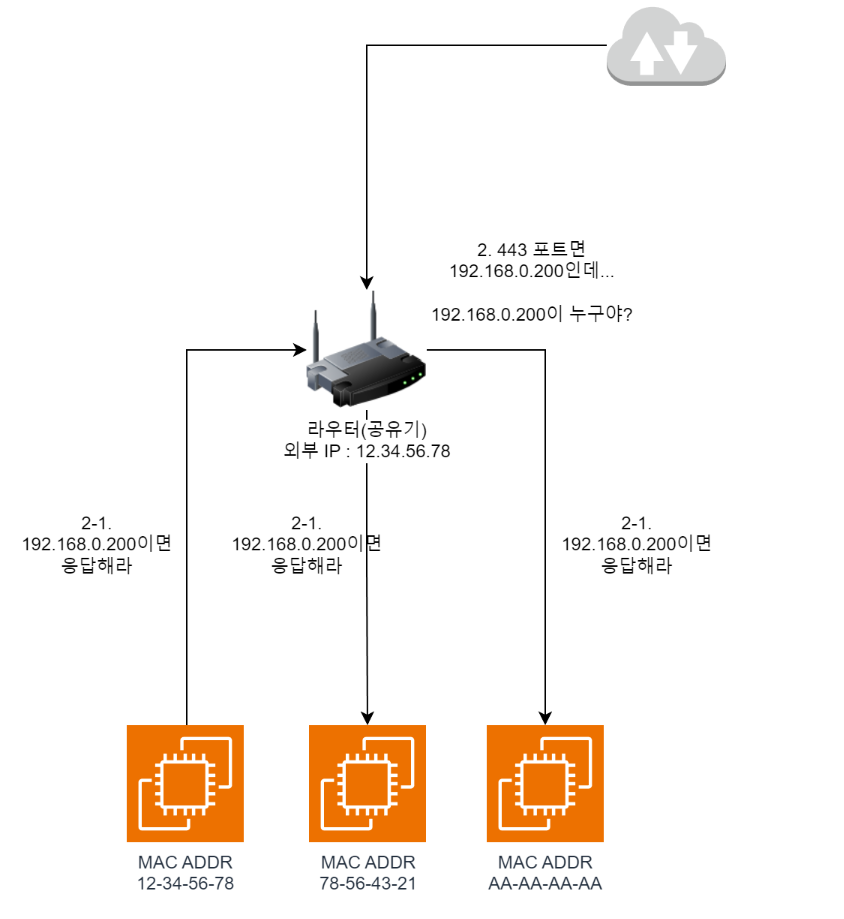
- 由于上面设置的
端口转发配置,路由器需要把流量转发到192.168.0.200。但是路由器目前不知道192.168.0.200这个地址,所以它会向内部网络中所有人广播谁拥有 192.168.0.200,请回应这样的请求。(ARP Request)
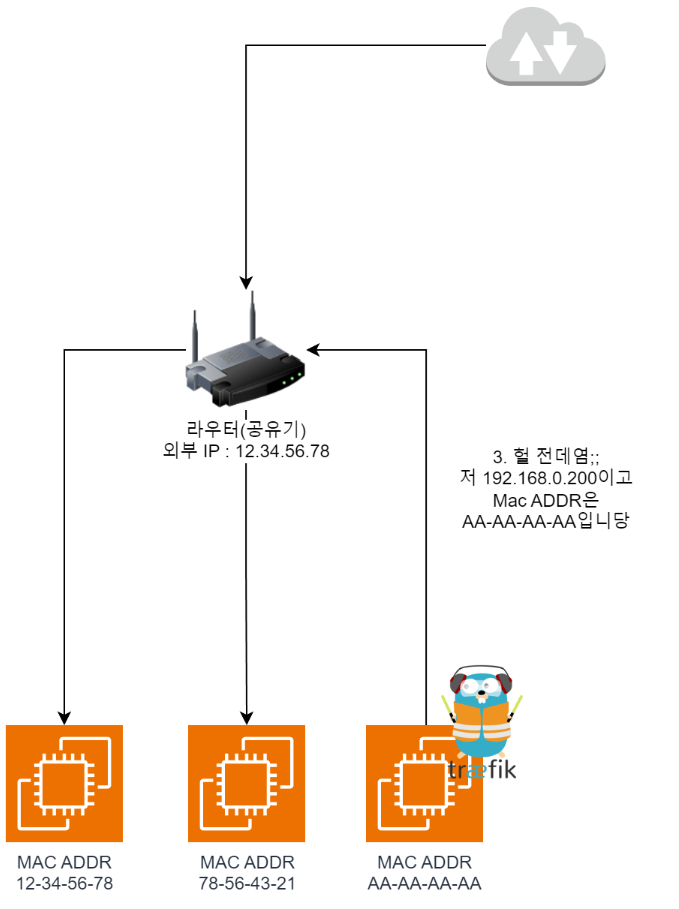
- 于是有 Traefik 的节点回应
啊是我;;,并附上自己的MAC Address。由此路由器知道,从外部进来的流量发往AA-AA-AA-AA即可。
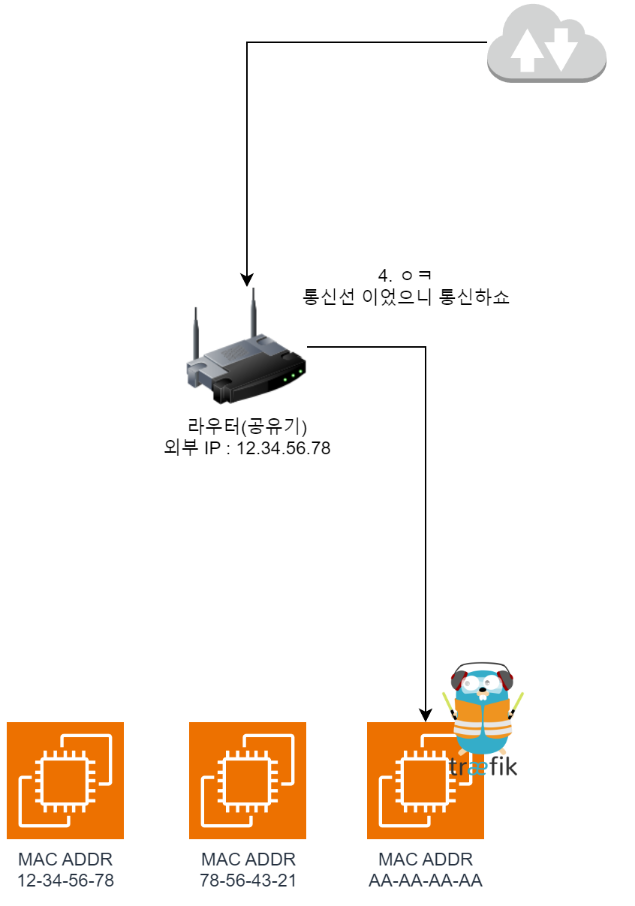
- 这样彼此就能转发流量,从而可以正常通信了。
容易混淆的点
那么?就会出现一些容易混淆的地方。逐条大致整理一下:
等等,那么一个节点可以拥有多个 IP 吗?
- 例如,刚才的例子里,AA-AA-AA-AA 应该已经从 DHCP 服务器获得了一个内部 IP。
- 那么这里又额外分配了一个 IP?是的,没错!
在 MetalLB 系统中,一个节点可以被分配多个内部 IP。
如果有 Traefik 的节点宕机了怎么办?
- 当然?短时间内会无法访问,处于宕机状态。
- 但是 Traefik 会被调度到另一个节点,之后再进行新的 ARP Request/Response,就会被转发到新的 MAC Address(节点),故障也就恢复了。
ARP Response 是由谁来回应的?
- MetalLB 容器负责 ARP Response,并把发往该地址的流量转发到 Pod(这里是 Traefik)。
结语
本文内容是我查阅文档进行的独立研究。(尤其是 MetalLB 相关部分)
如果有任何错误,欢迎随时指正,非常感谢!
IpTime 是在韩国家庭中非常普及的路由器品牌。 ↩︎
Comments