
注:筆者は韓国在住のため、本文には韓国特有の文脈が含まれることがあります。
最近、暇なときに論文を一つずつ読む趣味ができました。 その中で、arxivで面白い論文を一つ読んだので、まとめて共有してみようと思います。
論文タイトルは ChatGPT is a Knowledgeable but Inexperienced Solver: An Investigation of Commonsense Problem in Large Language Models (Arxiv Link
) です。
テーマは、大規模言語モデル(ChatGPT)は常識的な問題をうまく解けるのか? です。なかなか面白いテーマなので、自分の勉強も兼ねて共有も兼ねて、読んだ内容をまとめてみようと思います。
私は論文を読んだこともなく、学部の記憶もうろ覚えなので間違っているかもしれない点を予めお知らせします!(間違いがあれば教えてください、ヘヘ)
1. 要約
論文は次のような問いを投げかけます。
- GPTは常識に関する質問に効果的に答えられるか?
- GPTは常識をよく知っているか?
- GPTは特定の質問に答えるために必要な常識とそうでない常識を適切に区別できるか?
- GPTは与えられた常識を効果的に活用して質問に答えられるか?
そしてこれに対する簡単な答えは次の通りです。
- 効果的に答えられるが、社会規範、因果関係、時間に関連する特定の分野についてはうまく答えられない。
- ほとんどの常識をよく知っている。
- 質問に答える上で密接に関係する(必要な)常識とそうでない常識をうまく区別できない。
- 文脈の中で追加の常識を入力しても、うまく活用できない。
2. 常識の分類
研究者は常識を8つのカテゴリに分類しました。 それぞれ次の通りです。
1. 一般(General)常識(広く共有される常識)
- 太陽は東から昇る
2. 物理的(Physical)常識(物理的世界に関する知識)
- ガラスのコップは落とすと割れる。水は下に流れる。
3. 社会的(Social)常識(社会規範に関する知識)
- 助けてもらったら「ありがとうございます」と言うべき。
4. 科学(Science)常識(科学概念の原理/知識)
- 重力はすべての物体を地球の中心に引き寄せる。
5. 因果関係(Event)常識(因果関係および順序に関する知識)
- 水のコップを倒す → 水がこぼれる
6. 数字に関する(Numerical)常識(数字に関する常識)
- 人の手は2つで指は10本
7. 典型的な(Prototypical)常識(概念に関する知識)
- ツバメは鳥の一種であり、羽がある
8. 時間に関する(Temporal)常識
- 海外旅行は散歩よりも時間がかかる。
そして研究者は各カテゴリ別に常識に関連するデータセット11個を準備しました。
左からデータセット名 / カテゴリ / 例の質問 です。
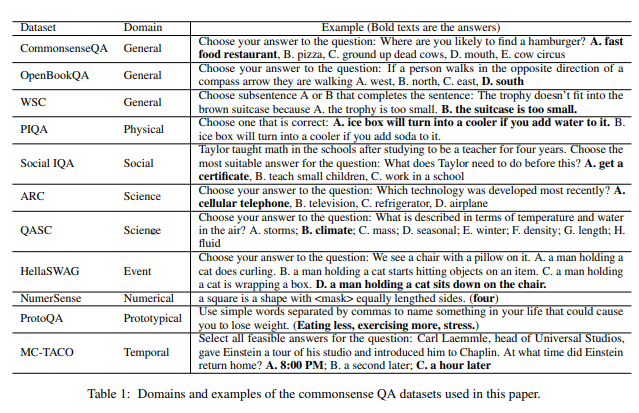
3. ChatGPTは常識質問に効果的に答えられるか?
研究者は上記のデータセットごとに100問ずつ問題を抽出し、GPT3、GPT3.5、ChatGPTモデルに尋ねました。
以下はGPT3、GPT3.5、ChatGPTの各質問に対する正答率です。
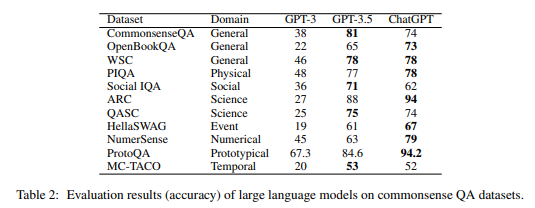
注目すべき点は次の通りです。
- 全体的によく答えている
- Science分野は約94%で最も高い正答率を示した。
- 社会規範(Social)、因果関係(Event)、時間(Temporal)に対する正答率は低い(70%未満)
- 全体的にGPT 3.5モデルに比べ、チューニングモデルであるChatGPTの精度が高い
- 一部の質問についてはGPT 3.5の正答率が高いように見えるが、これはChatGPTが「与えられたデータだけでは正解が分かりません」という回答を出して生じた錯覚に近い。
4. ChatGPTは質問に答えるために必要な常識とそうでない常識をうまく区別できるか?
研究者は上記の質問データセットから、各データセットごとに20問を再度抽出しました。
その後、GPTに「この質問に答えるためにどんな知識が必要か」を尋ね、人間の回答を基にPrecision(適合率)、Recall(再現率)、F1 Scoreを求めました。

Precision? Recall? 難しい言葉が出てくるので一度整理してから入りますね。
Precision : GPTが出した答えの正確さ
- GPTの回答のうち正解は何%か?
- 例えば5つの回答のうち3つが正解、2つが不正解ならPrecisionは60%
Recall : 全体の正解のうちGPTが見つけた正解の数
- 人が予測した正解のうち、GPTが何個見つけたか?
- 例えば予測正解が5つで、GPTが回答10個のうち4つが正解、6つが不正解ならRecallは80%(4/5)
- Recallを計算するとき不正解は重要ではない!
F1 Score : PrecisionとRecallの調和平均
- Precisionだけを指標にすると? : 確率の最も高い答えをたった1つだけすればいい
- Recallだけを指標にすると? : 答えを10000個ずつ書けばその中のいくつかは当たる
- しかし私たちが望むのは「正確な答えを」「十分多く」してくれるAIモデル
- したがってPrecisionとRecallの調和平均を取ると「正確度」に近い指標が出る!
- つまりF1 Scoreが高い == よく答えた!
難しい話をしましたが!結論的には、次のような結果が得られました。
- GPTはPrecisionは低いがRecallは高い
- 全体データセットでPrecisionは55.88%だが、Recallは84.42%
- つまり、質問を解決するのに必要な知識をほぼほとんど教えてくれるが、精度は高くない
- GPTは科学分野では比較的性能が良いが(F1 74〜76%)、社会規範、時間分野で特に性能が低い(F1 50%以下)
5. ChatGPTは常識に博識か?
研究者は3.で生成された必要な知識を基に質問プロンプトを手動で作成しました。その後、GPTが生成した回答が正解か不正解かを手動で評価しました。

上記の質問の場合はChatGPTが生成した不正解の例です。
GPTは blowing into a trash bag and tying it with a rubber band may create a cushion-like surface, but it is unlikely to be durable or comfortable for prolonged use as an outdoor pillow (翻訳:ゴミ袋に空気を入れて輪ゴムで縛ればクッションのような表面を持つが、屋外用枕として長く使うには耐久性に劣るか快適ではないだろう)と答えましたが、ゴミ袋で枕を作るのは一般的な慣行なので不正解として処理したそうです。
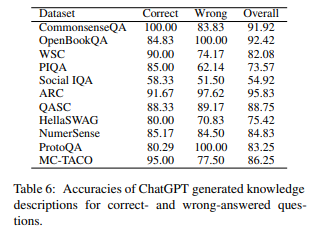
上記の結果表によると、研究者は次のような結果を得ました。
- GPTは博識であり、質問に答えるためのほとんどの常識を知っている。
- 全体データセットで平均82.66%の正確度を示した
- ほとんどのデータセットで70%以上の正確度を示した。
- ただし、社会規範領域では54.92%と性能が低い。
- しかし、GPTの回答には誤解を招くものや、過度に一般化されて不要な知識も含まれている
- 全回答の26.25%に関連性が低く誤解を招く情報が含まれている。
- 15%程度の説明が過度に一般化されており、質問の回答に必要な具体的な情報ではない
6. ChatGPTは応答時に対話の文脈で追加された常識を活用して、回答に活用できるか?
研究者はGPTが文脈から出てきた常識を使って回答に活用できるか確認するため、4.のようにGPTに質問に答えるとき必要な常識を推論させた後、同じ質問に再び答えさせて回答が評価されるか確認しました。

上記の例は、以前不正解だった回答が追加説明を生成した後でも変わらない例を示しています。
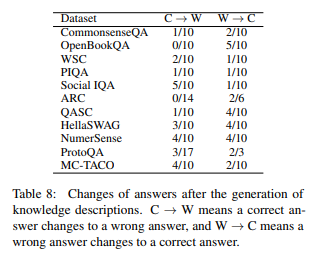
上記の結果表によると、研究者は次のような結果を得ました。
- GPTはGPTが生成した常識説明を対話文脈に追加するだけでは、効率的に回答に活用できない。
- 文脈に説明が追加される場合、正解が不正解に変わる場合(C->W)および不正解が正解に変わる場合(W->C)が両方存在
- Social IQAデータセットの場合、文脈に追加された常識が間違っており、むしろ正解が不正解に変わるもの(5個)が、不正解が正解に変わるもの(1個)より多かった。
- 研究者は既にモデルに生成された知識があり、単純に追加情報を生成することが大きな効果がないと推測している。
さらに、対話文脈に「GPTが生成した常識」ではなく、「ユーザーが直接正しい常識」を追加しても正答率が100%にはならなかった。
- 人がアノテーションを付けたCoS-E、ECQAデータセットを基に対話文脈に正解(Golden Knowledge)を追加した。
- CoS-Eは不正解→正解が4個増加
- ECQAは不正解→正解が8個、正解→不正解が1個増加
- 研究者は複雑な推論(例えば否定推論)などを活用できる能力が不足していると推測
- 否定推論の例
- Q: バスケットボールに穴が開いたが、形がそのままなら間違っているのは?
- A: 穴が開いた、B: アメリカで人気がある、C: 空気が満ちている
- CoS-Eデータセットは「穴が開いた物体には空気が留まれない」と説明したが、GPTは依然としてAを予測
- 否定推論の例
// TODO : もっと書く…
Comments