
注:筆者は韓国在住のため、本文には韓国特有の文脈が含まれることがあります。
これから作るオーディオを聴いてみよう(日本語)
1. TTSとは?
Text-To-Speechは文字通り、テキストを音声データに変換するソフトウェアのことです。
一度作っておけば、呼び出し回数を気にせず多くのAutomationで使えるので、自分で作ってみることを目標にしました。
どうせ作るなら、自分の知っているキャラクターが話してくれた方が楽しいですよね。そこで、カスタムデータを使って自分でモデルをチューニングし、TTSを作ってみる予定です。
その中でも、Bert-Vits2 というモデルを利用して学習する予定です。ちなみに、中国語、英語、日本語に対応しています。
もしキャラクターの声には興味がなく、整った韓国語の声が必要!という方は Melotts と Pretrained モデルを探してみることをおすすめします。
最後に付け加えると、モデルを作ったあとはモデルの配布などはせず、個人研究用・趣味用にのみ使用することを強くおすすめします。
用意するものはGPU搭載のUbuntuサーバーと根性です(…)。
2. 作業プロセス
学習のためには、少なくとも20分〜1時間程度のクリーンな音声データが必要です。
自分で録音できれば一番良いのですが、中国語・日本語・英語のデータを20分〜1時間発話するのは簡単なことではありません。
そこで、私たちはアニメを使って学習資料を作る予定です。
アイデアは次の通りです。
- 字幕には字幕の開始時刻と終了時刻、テキストデータがある。
- アニメから字幕の時間分だけ切り出して音声データを抽出し、その音声データのLabelを字幕の値とする。
そして、全体のプロセスは次の通りです。
- 好きなアニメと、その原語字幕を入手します。
- 字幕データとアニメデータを読み込み、セリフ部分を抽出します。
- セリフ部分を抽出した後、機械学習で背景音楽などを除去します。
- 自分でセリフを一つ一つ聞きながら、欲しいキャラクターではないデータを削除します。
- すると「欲しいキャラクター」の「音声データとラベルデータ」が集まります。このデータでBert-VITS2を学習させます。
- 完成したTTSで遊んでみましょう!
このプロセスに沿って簡潔に説明していきます。
3-1. 字幕ファイルからセリフ部分を抽出する
アニメ、原語字幕は各自で用意するものとして省略します。
私が使った素材を集めた Github にアクセスします。
git clone後、依存関係をインストールし、extract_wav_1.py に動画名と字幕ファイル名を入れて実行します。
すると、dataフォルダに 1〜xxx.wav ファイルが自動で生成されます。
3-2. UVR (ULTIMATE VOCAL REMOVER) を使って背景音楽を除去する
UVRのホームページ に行ってダウンロードして実行します。
その後、次のように設定を合わせてください。
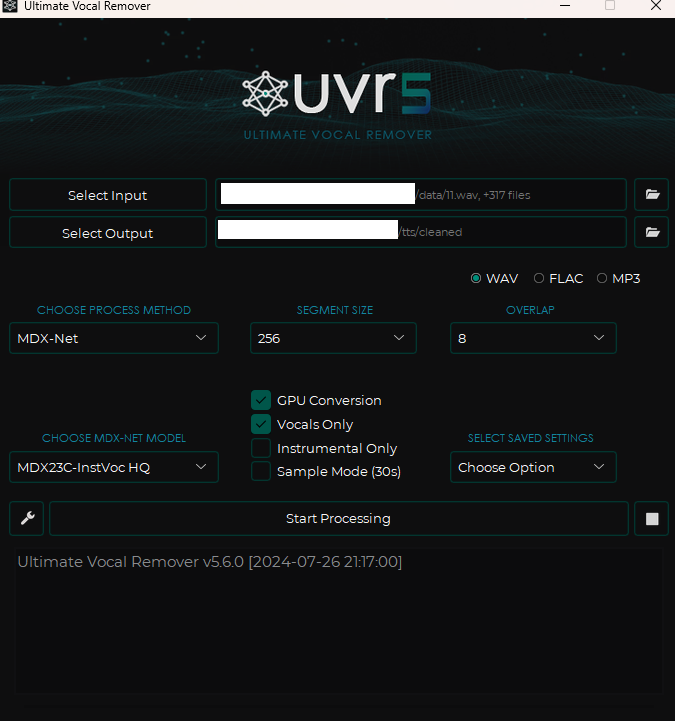
- inputには先ほど生成したwavファイルをすべて入れます。
- outputには cleaned というフォルダを作って入れてください。
- Choose MDX-NET Models は、Download New Model -> MDX-Net で MDX23C-InstVoc HQ モデルをダウンロードしてから選択します。
- GPU Conversion、Vocals Only オプションをオンにして実行します。
3-3. 手作業で低品質オーディオ・他キャラクターのセリフを除去する
cleaned フォルダに入って、低品質オーディオ(足音や効果音が混ざっている場合、声が混ざっている場合)と、他キャラクターのセリフを除去します。(ファイル削除)
3-4. ラベルデータを作る
change_name_2.py を実行して cleaned フォルダのファイル名を変更し、
make_list_3.py を実行して esd.list というファイルを作成します。
3-5. 集めたデータの長さを確認する
calculate_length.py を実行して、何分何秒分のデータを集めたかを確認します。
3-6. 繰り返す
もし十分なデータが集まっていなければ、データが集まるまで前の作業を繰り返してください。
別のディレクトリにキャラクター名でフォルダを一つ作り、次のように配置します。
キャラクター名/
ㄴesd.list
ㄴraw/
ㄴf6df34d9-01c4-4db9-97e9-a35795a5f64b.wav
ㄴ18bcc2c6-3e23-427c-a04a-9414b6f0b85e.wav
...esd.listはテキストエディタで開いて続けて貼り付けていけば良く、 rawフォルダにはcleaned内のwavファイルを貼り付ければOKです。
これを繰り返して、ファイルの合計長さが20分〜1時間になるようにしましょう。
3-7. データを学習する
Ubuntuサーバーに移します。
UbuntuにCUDAがインストールされていなければ、「Ubuntu CUDA インストール」と検索してCUDAをインストールします。
Bert-Vits2
リポジトリをCloneし、仮想環境
を作ったあとに pip install -r requirements.txt を実行して依存関係をインストールします。
その後 python webui_preprocess.py を実行します。
その後、該当のGradio環境にアクセスしてファイルをそれぞれダウンロードして所定の位置に入れます。

中文 RoBERTa -> BERT_VITS2/bert/chinese-roberta-wwm-ext-large フォルダに flax_model.msgpack, pytorch_model.bin, tf_model.h5 をダウンロードして入れる
残りも同じく、容量の大きいファイルをダウンロードして入れていきます。
日文 DeBERTa -> Bert-VITS2/bert/deberta-v2-large-japanese-char-wwm フォルダ
英文 DeBERTa -> Bert-VITS2/bert/deberta-v3-large フォルダ
WaveLM -> Bert-VITS2/slm/wavlm-base-plus フォルダ
その後、Bert-VITS2/data/{キャラクター名} フォルダを作成し、学習データを移します。
Bert-VITS2/
ㄴdata/
ㄴElaina/
ㄴesd.list
ㄴtrain.list
ㄴval.list
ㄴraw/
ㄴf6df34d9-01c4-4db9-97e9-a35795a5f64b.wav
ㄴ18bcc2c6-3e23-427c-a04a-9414b6f0b85e.wav
...このとき、esd.listは作成したファイルそのまま、 val.listは esd.list の最後5%程度をコピー&ペースト、 train.listは val.list に入れたものを除いてコピー&ペーストして作成すればOKです。
例:
esd.list
f6df34d9-01c4-4db9-97e9-a35795a5f64b.wav|Elaina|JP|ありがとう
b234c567-d890-1234-e567-890f123g4567.wav|Elaina|JP|おはよう
c345d678-e901-2345-f678-901g234h5678.wav|Elaina|JP|すみません
d456e789-f012-3456-g789-012h345i6789.wav|Elaina|JP|さようなら
e567f890-0123-4567-h890-123i456j7890.wav|Elaina|JP|元気ですか?train.list
f6df34d9-01c4-4db9-97e9-a35795a5f64b.wav|Elaina|JP|ありがとう
b234c567-d890-1234-e567-890f123g4567.wav|Elaina|JP|おはよう
c345d678-e901-2345-f678-901g234h5678.wav|Elaina|JP|すみません
d456e789-f012-3456-g789-012h345i6789.wav|Elaina|JP|さようならval.list
e567f890-0123-4567-h890-123i456j7890.wav|Elaina|JP|元気ですか?ここまで終わったら、先ほどのGradioに行って次のように設定します。
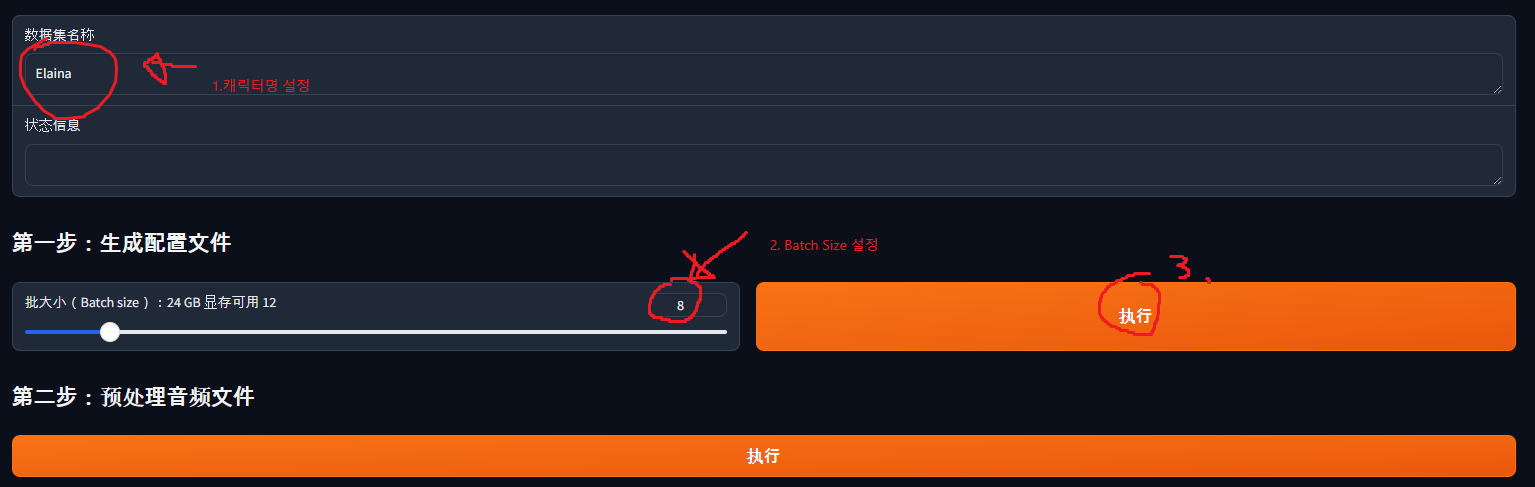
- キャラクター名(私の場合は Elaina)を入力します。
- バッチサイズを選択します。バッチサイズが大きいほど学習は速くなりますが、大きすぎるとGPUメモリに乗り切らなくなります。私は3090なので12に設定しましたが、まずは大きめで試して、後から減らせばOKです。
- すべて設定したらボタンを押します。
ボタンを押すと、Bert-VITS2/config.yml ファイルが作成されます。 このファイルを修正します。
- 7行目の “Data/” 部分を “data/{キャラクター名}” に修正します。(私の場合は data/Elaina)
- 20行目の in_dir を “audios/raw” -> “raw” に変更します。
- 22行目の out_dir を “audios/wavs” -> “wavs” に変更します。
- 29行目の transcription_path を “filelists/esd.list” に変更します。
その後Gradioに戻り、第二步:预处理音频文件(ステップ2:オーディオファイルの前処理)、第三步:预处理标签文件(ステップ3:ラベルファイルの前処理)、第四步:生成 BERT 特征文件(ステップ4:BERT特徴量ファイルの生成)を順番に押していきます。
その後、Pretrainedモデルをダウンロードします。
次の リンク に移動して DUR_0.pth, D_0.pth, G_0.pth, WD_0.pth をダウンロードし、data/{キャラクター名}/models フォルダに貼り付けます。
その後、config.ymlの90行目の config_path を “configs/config.json” に変更します。(train_ms 部分)
その後、Bert-VITS2 フォルダで torchrun --nproc_per_node=1 train_ms.py を実行すると学習が進行します!
3-8. 音声を出力する
学習が進むと、音声が正常に出るかを確認する必要があります。
data/{キャラクター名}/models フォルダを見ると、学習が進むにつれていくつかのファイルが生成されます。たとえば G_1000.pth のような形です。
G_xxxx.pth ファイルが、声を生成するためのファイルです。 該当フォルダを確認した後、config.yml の105行目(webui部分)の model を “model/G_xxxx.pth” に変更します。(このとき xxxx は現在のディレクトリにあるモデル)
その後、Bert-VITS2 フォルダで python webui.py を入力するとGradioが起動し、そのGradioでTTSをテストできます。
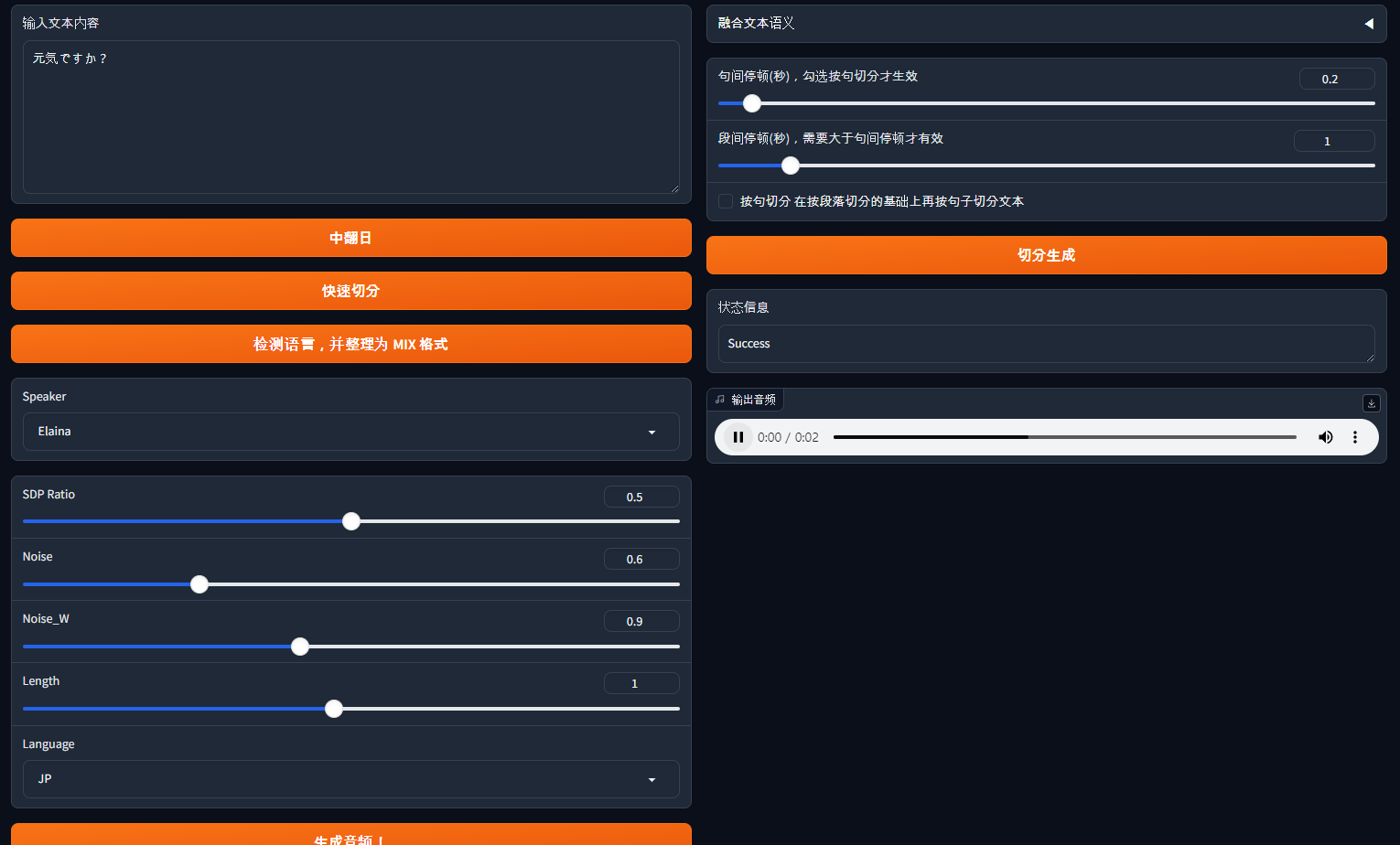
ちなみに、このデータを使って別途サーバーを作りたい場合は、hiyoriUI.pyを参考にしてみてください!fastAPIベースのサーバーを提供しています。
おわりに
これで簡?単にTTSを作る方法についてお話ししました。
ところどころ穴が空いていますが、似た記事があるので、その記事で混乱した部分を中心に取り上げたためです。
Chapter 4. Bert-VITS2 事前準備および訓練開始
本記事で抜けている部分は、この記事も合わせて読むと理解が早いと思います。
私の場合、別途回している機械学習サーバーにTTSを移植してうまく使っています。
うまくいかない部分があれば、お気軽にコメントください。皆さんも楽しいTTS作りを!
Comments