注:筆者は韓国在住のため、本文には韓国特有の文脈が含まれることがあります。
こんなサービスを作った話です!
2024.06.30 追記:当時はまだ ChatGPT が登場する前で、こういったチャットボットサービスは珍しかったんです!
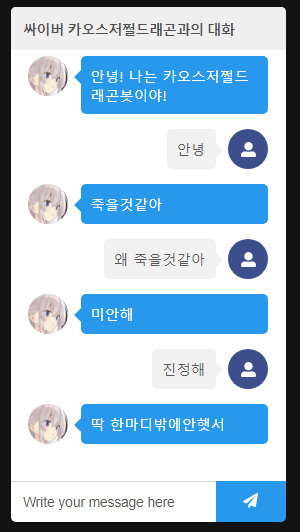
うわあああ一体何が起きているんですか!!
1. なぜこれを開発したのですか?
元々は長々と書いていたのですが、他人の TMI はあまり面白くなさそうなので簡単に書きます。それでも結構長いですが!
趣味でディープラーニングを利用した自然言語処理入門 を読んでいて、BERT の文章埋め込みを利用した韓国語チャットボット のパートで、「学習データをツイートベースにできそうじゃない?」とふと思いました。
あれ、これ……Twitter のメンションでも似たようなことができるんじゃない?
こんな感じで作れるんじゃないかな?
問題は学習データの数で、Twitter API は最近のツイートを要求した際、最大で 3200 件までしかツイートデータを提供してくれません。
保守的に、このうち半分が公開ツイート(虚空に向けて書くツイート)と仮定すると、約 1600 件のツイートが学習データになるのですが、ご存知の通り機械学習において学習データ 1600 件は非常に少なく、意味のあるチャットボットを作るのは困難です。
でも面白そうなら、とりあえずやってみる価値はあるんじゃないでしょうか?
ということで、作ってみることにしました。 ああ……あの時は知りませんでした。約 200 行ほどの Colab コードをサービス化するために、1 か月以上を溶かすことになるとは……。
2. Serverless ML?
機械学習で変換されたデータを作る、ごくごく単純な構造は次のとおりです。

つまり、サーバー 1 台で 1 件ずつ処理すると、1 人あたり約 15 分かかります!
ということは、ざっくり 1 時間あたり 4 人処理可能ですね! 100 人なら 25 時間、 1000 人なら 250 時間ですから……
今日サービス登録すると、10 日後に完了します!
しかもこれ、チャットボットの質問/回答は除いた値です!
ああ……これはちょっと……何とか別の方法を考えないと……
あ!考えてみると、サーバーレスアーキテクチャを使うと良さそうです。 サーバーレスの概念をご存知でない方もいらっしゃると思うので、簡単に図で説明します。
これが従来のクラウドの使い方です。1 か月、1 週間、1 日など決められた期間だけコンピュータを借り、借りた時間分だけお金を払います。VPS というのもこれに近い概念です!
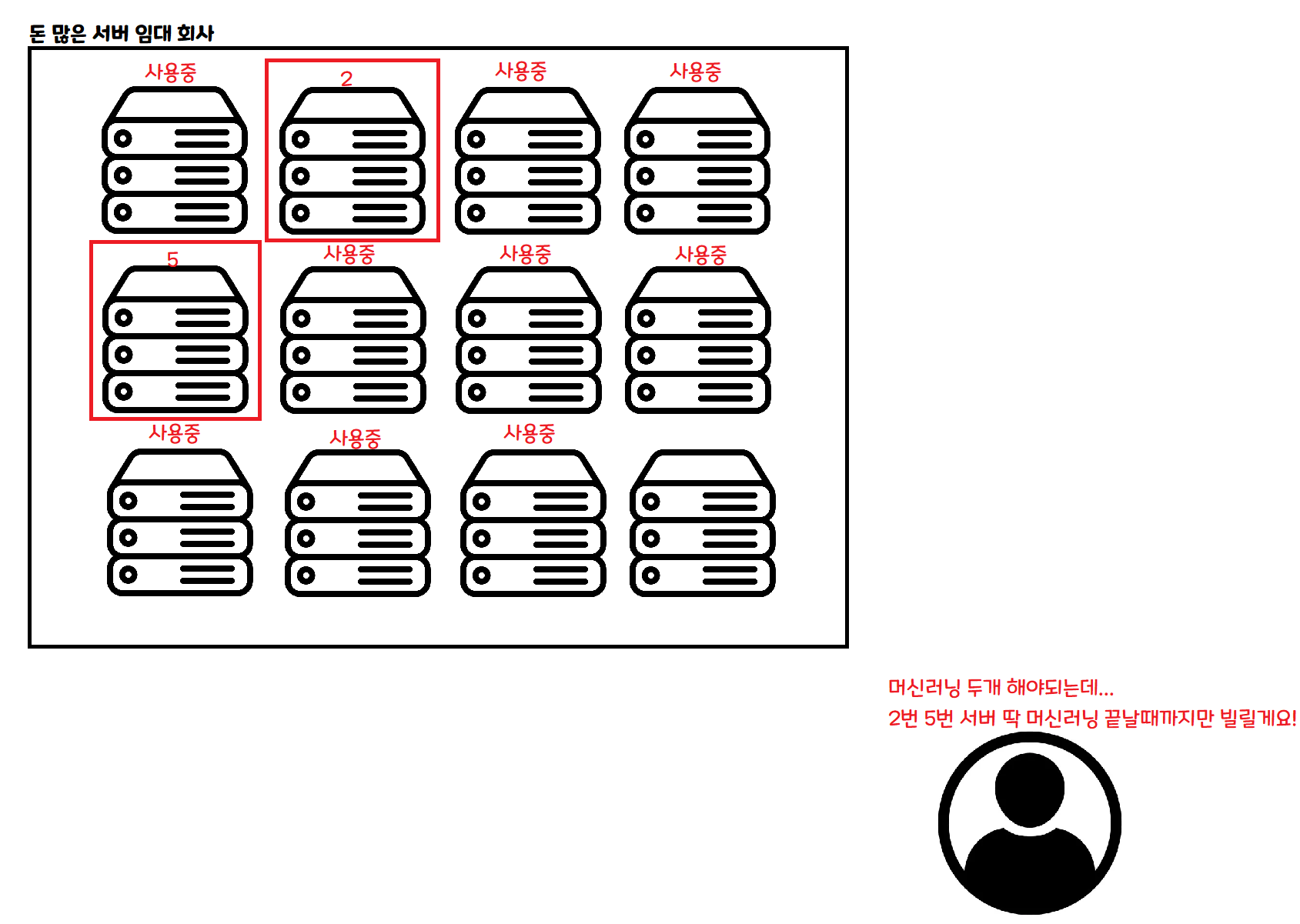
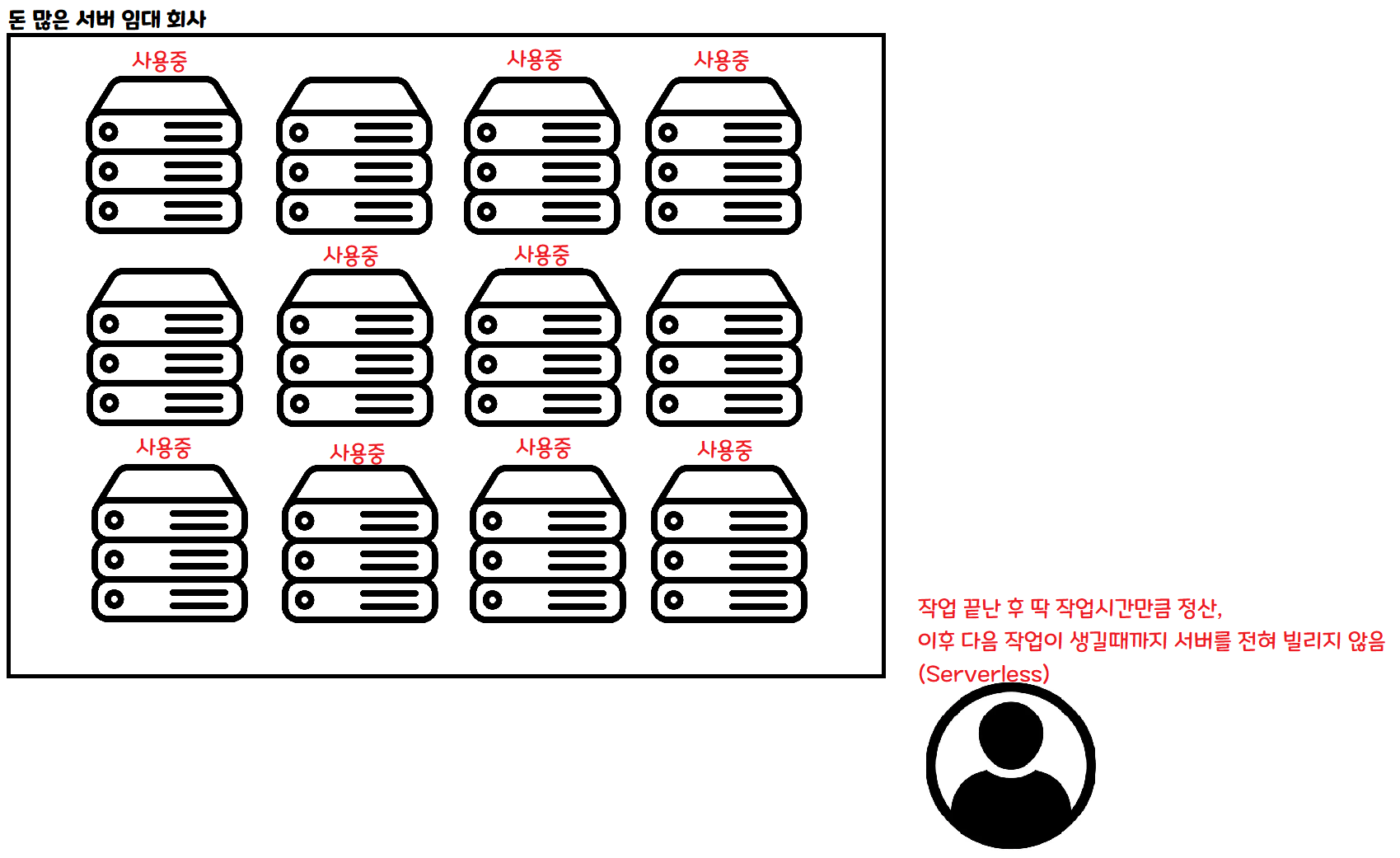
こちらはサーバーレスの方式です。何か作業をする際に、必要な分だけ要求すると、ちょうどその作業が終わるまでだけ借りることができます。
もし同時に 100 人入ってきたら、100 台のサーバーを同時に借りて処理することができます。 もし誰も入ってこなければ、その間はサーバーを借りなくても構いません。
このようなアーキテクチャを適用すれば、理論的には何人入ってきても 1 人入ってきたのと同じ速度でデータを処理できます! もちろん実際には別の問題もあります。
あ!問題解決ですね!とりあえずこれでやってみましょう!
3. 甘くない現実
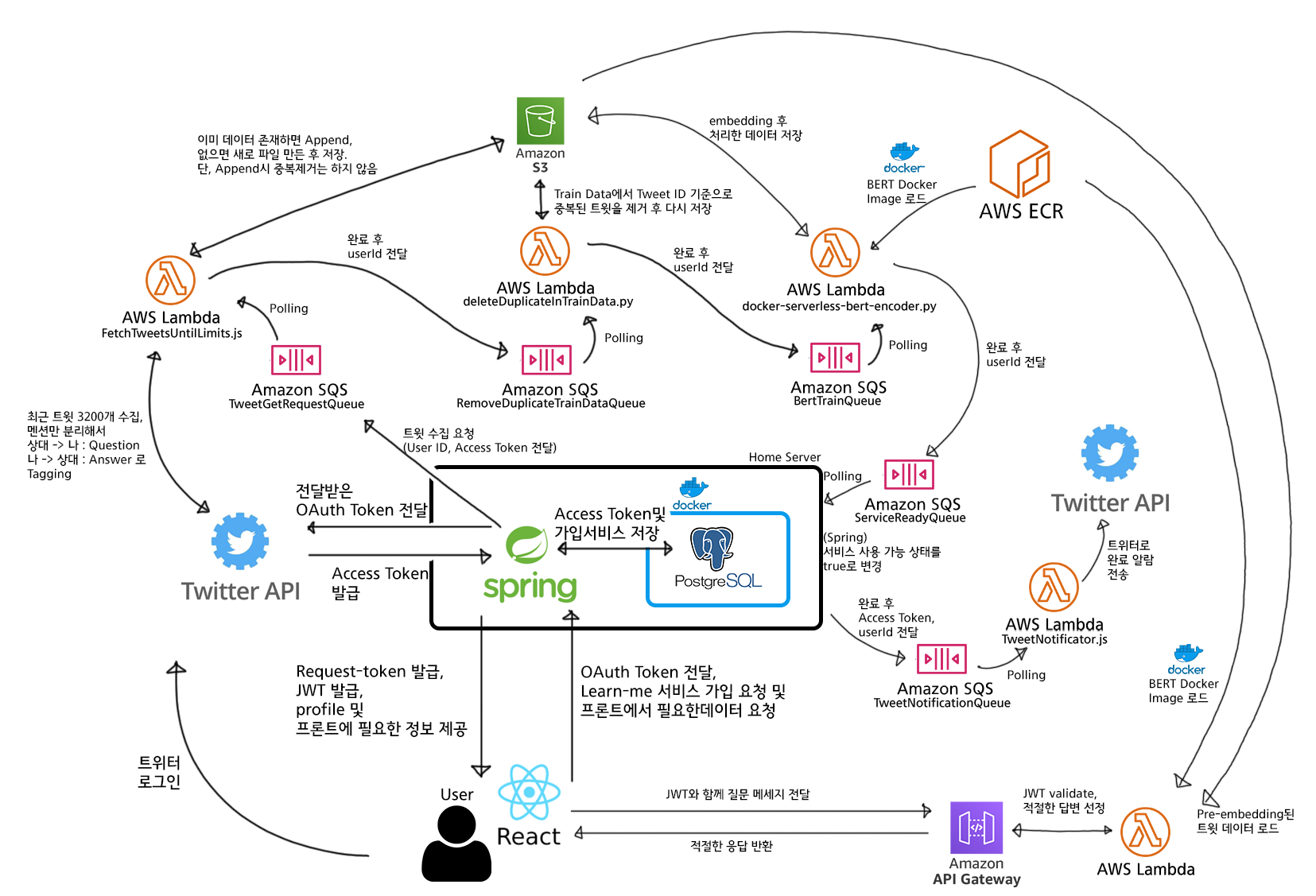
なんとなくこうすればいいと思っていたのですが……
ああ……。 皆さんも急に頭が痛くなってきましたよね? これをごくごく簡単にまとめると次のようになります。
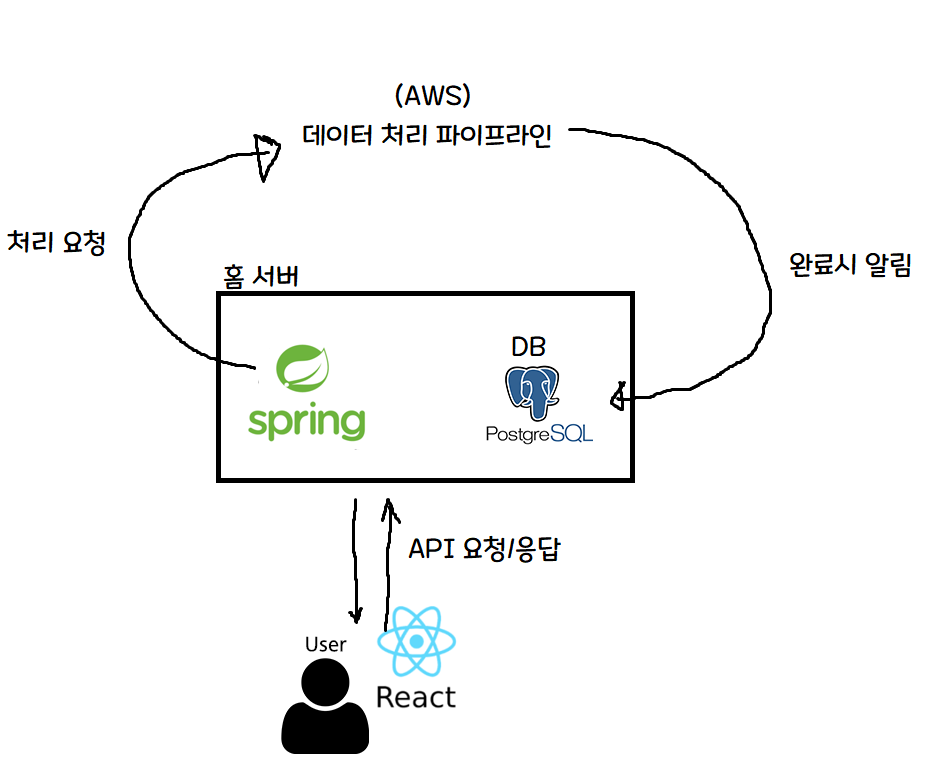
あ、こうすると少し分かりやすくなりますね!
核心的な部分は次のとおりです。
- サーバー代を節約するため、会員登録/認証トークン発行などはホームサーバーの Spring サーバーが処理する。
- 重い演算である機械学習は、クラウド(AWS)にリクエストを送り、AWS のサーバーリソースを活用して処理する。
- AWS で処理が完了したら、ホームサーバーに通知し、処理完了の事実を DB に保存する。
個人的にホームサーバーを使っているので、軽い演算はホームサーバーで処理してサーバーレンタル代を減らし、重い演算はクラウドサービス(AWS)に任せてコスパとパフォーマンスの両方を取ろう、という夢と希望を持ってサービスを作りました!
4. ローンチ — 副題:ボトルネックは予想外のところで起きる
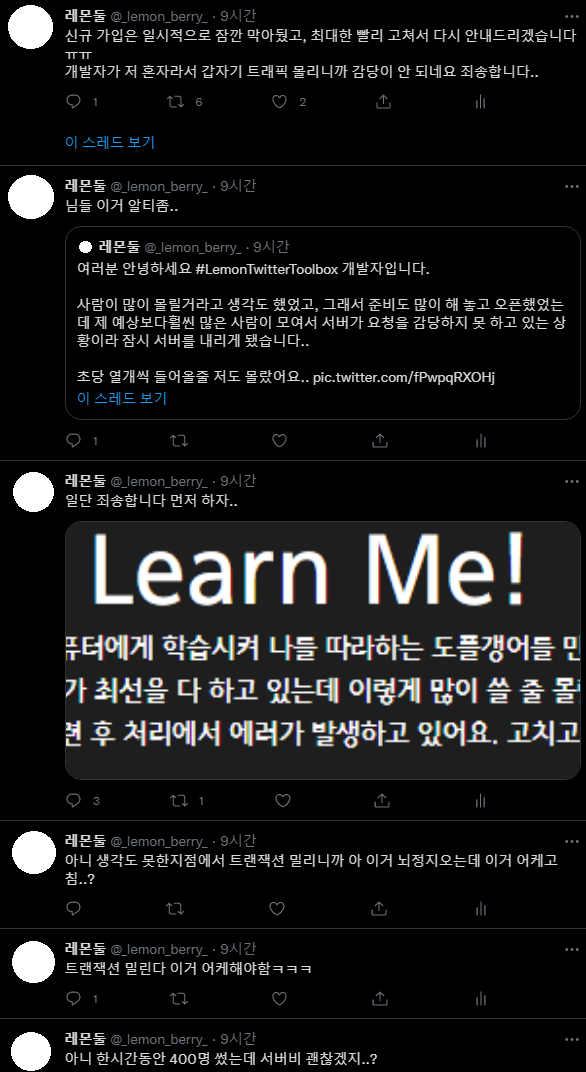
申し訳ありません……いやその、計画は確かに完璧だったはずなのに……
当然、このプロジェクトのボトルネックは機械学習の部分になると思っていて、それに合わせてシステム全体を組んだのですが、意外にも……そうではありませんでした。
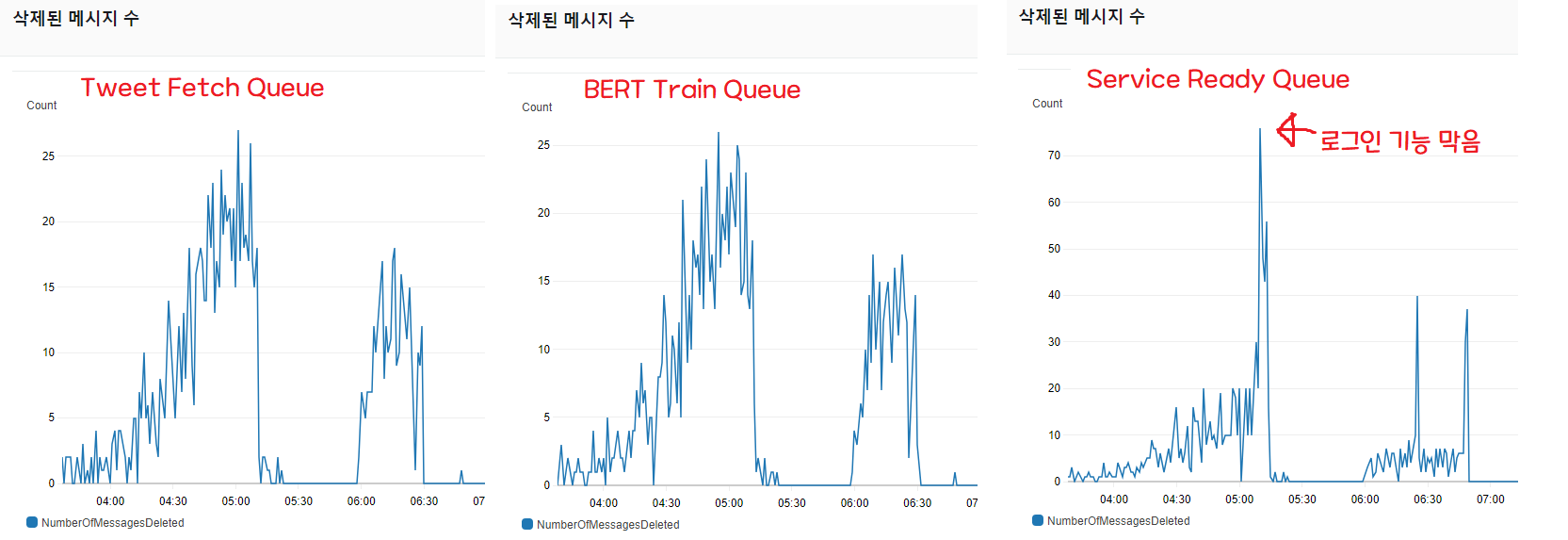
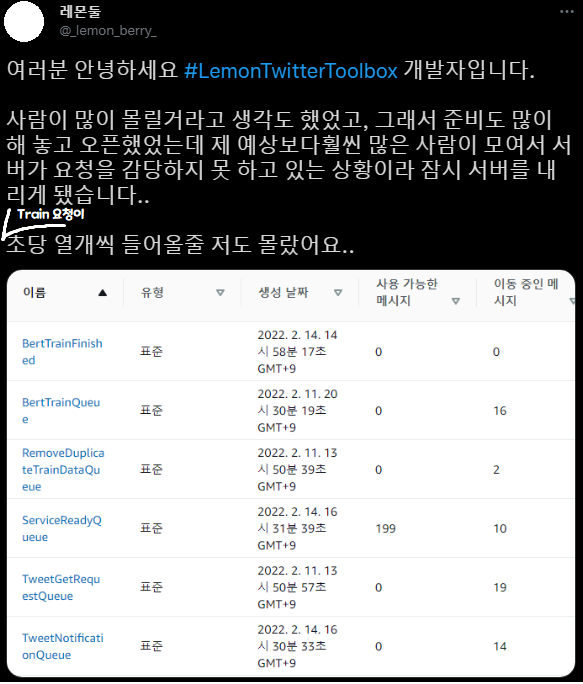
削除されたメッセージ数は処理量を測れる指標です。 リクエストがメッセージの形で入ってきたとき、1 分間に何件のリクエストを処理してメッセージを削除したかを示しています。
ご覧のとおり、ツイート 3200 件を取得するスクリプトと BERT で機械学習処理を行うキューは似たような動きをし、リクエストをすべて捌いていることが分かります(1 番、2 番のグラフ)。
しかし、すべてのパイプライン作業が成功したときに Spring に処理完了を通知し、DB の「使用可能」フィールドを true にするキュー(3 番)が処理量に追いつけていないことが分かります。
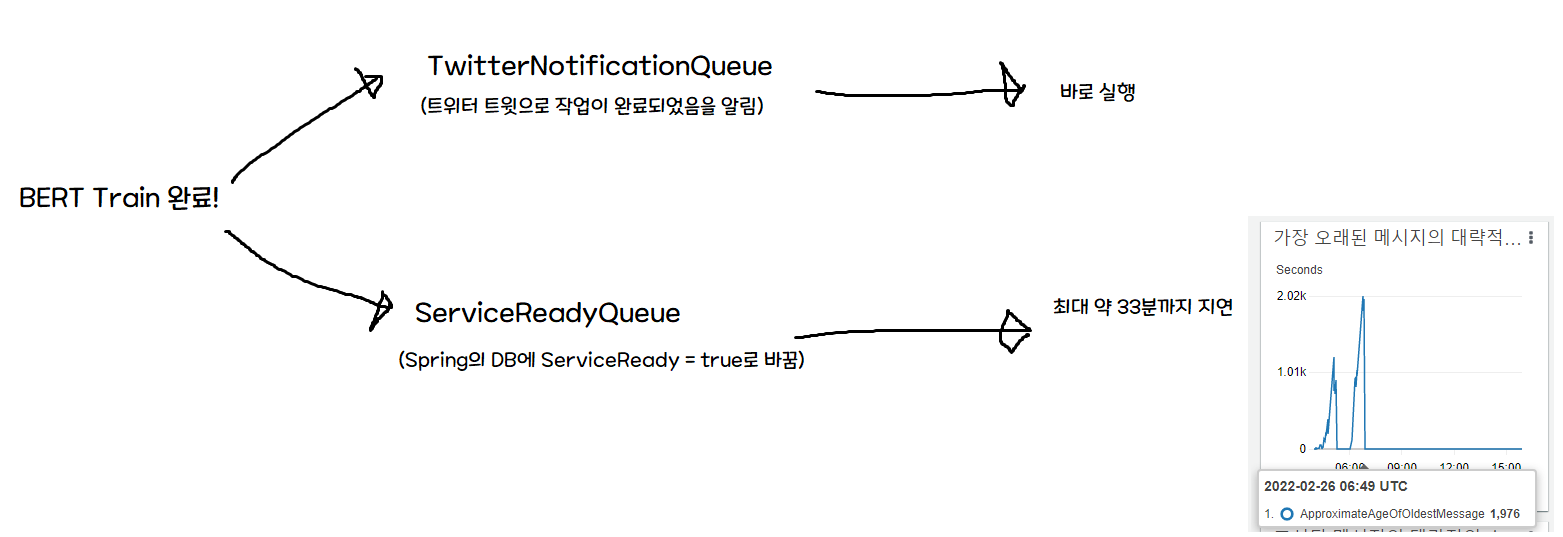
問題は、初期アーキテクチャでは ServiceReadyQueue が即座に処理されることを前提にしていた点です。
そのため、Train 完了時に Twitter 通知(サーバーレス)と Spring 通知が同時に行くのですが、このとき Twitter 通知はすぐ届くものの、DB 書き込みには遅延が発生します。 つまり、通知を受けて来たユーザーが最大 33 分間「ご利用いただけません!」画面を見ることになる問題が発生しました。
正直、ここではかなり悩みました。
ああ……一生受けられないようなトラフィックなのに……ログインを止めるか……止めるべきだよな……? 30 分も遅延しているのに……?
Spring が分間 10 件のメッセージを Consume するので、サービスに登録するユーザーが 6 秒に 1 人以下なら、ボトルネックは自動的に解消されます。しかしモニタリングの結果、減る気配が一向になかったので、ひとまずログインを止めることにしました。
基準は明確で、処理が遅れることは構わないが、処理が完了したと表示されたのにサービスを使えないことは非常に大きな欠陥だと考えたからです。
そこで、急遽 React プロジェクトを修正してログインボタンとサービス登録ボタンを外し、次のようにパイプラインを応急的に修正しました。

このようにすると、処理速度は変わりませんが、通知を受けて来たのに使えない場合というクリティカルなケースを避けることができます。
その後、しばらく DB 書き込みが完了するまで(溜まった作業が処理されるまで)時間を置き、再びログイン/登録ボタンを復活させました。
その後は思った通り正常に動作しました。ボトルネック自体は解消されていませんが、少なくとも完了通知を見て来た人が数十分間サービスを使えないというクリティカルなエラーは回避できました。
そしてモニタリングしながら原因分析をしていたところ、メッセージ処理量が最大 10 件で固定されているのに気づき、関連内容を調べていて、spring-cloud-aws の issue でこちら の issue を見つけました。要約すると、一度に 10 件のメッセージしか処理できず、非同期ではなく同期で動作する問題があるとのことです。
現在もオープンになっている別の issue を見ると、この問題は大規模なリファクタリングが必要で、3.0.0 で修正予定とのことです。結論的には……
ああ……じゃあホットフィックスは難しいな……
結論として、ボトルネック自体を簡単に解決することはできず、これを解決するには Spring がやっている仕事自体をサーバーレスアーキテクチャに書き直すか、ライブラリの依存関係を作り変える大工事(……)が必要だという結論に至りました。何にせよ、ローンチ直後の今日やることではないので、もう少しモニタリングすることにしました。
あっ!
今度は別のキューにメッセージが溜まり始めました。ツイート 3200 件を取得するキューです。 すぐにモニタリングに入り、当該キューを処理する Lambda 関数のエラー率が次のように 100% まで上がっているのを確認できました。
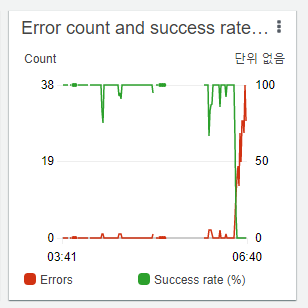
これは見るまでもなく API リミットですね!
CloudWatch に入って、当該 Lambda Function のログを開いてみると、案の定でした。
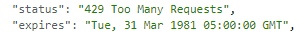
やっぱり API リミットだ!
どんな種類のリミットかは分かりませんが
(Twitter にはユーザーリミット、アプリリミット、15 分リミット、1 日リミット、1 か月リミットなど、色々な種類の制限があります……)
サービス登録ボタンを外さなければならないことは明らかでした(……)。
サービス登録ボタンを外し、Twitter に関連告知を上げ終えると、嵐のような 3 時間が過ぎていました。
1 日のリミットを食らってこれ以上できることがないので(……)、サービスの検死をして記録を残そうと思い、今これを書いています。
5. 結論および後記
ああ……SQS -> Spring へ向かう箇所がボトルネックになるとは思いもよらず、 ずっと夢見ていたけれど、急に多くのトラフィックが押し寄せてサーバーが耐えられなくなった時のパニック状態を、初めて経験したような気がします。
特に、サービス全体を自分で作ったので(……)障害箇所はすぐに見つけられたと思いますが、ライブサービス中のサービスをどう直すか? 副作用はどうなるか? などを考えるのが一番大変だったと思います。
特に途中のように、**「サービスに重大な障害が発生した場合(通知は来たのに実行できない)」**ライブサーバーで素早く直さないといけないのに、急いで書いたコードがどんなサイドエフェクトを起こすか分からないまま急いでホットフィックスをするのは、心理的にも負担で、一番冷や汗をかいた瞬間だったと思います。
正直、一番強く感じた内容は
ああ、だからみんな自動化テスト、自動化テストって言うんだ…… テストがたくさんあれば、似たケースが起きてももう少し安心して修正できるんだなあ
ということでした。
そして意図しなかったのですが、AWS の恩恵を大きく受けた部分があって(?)
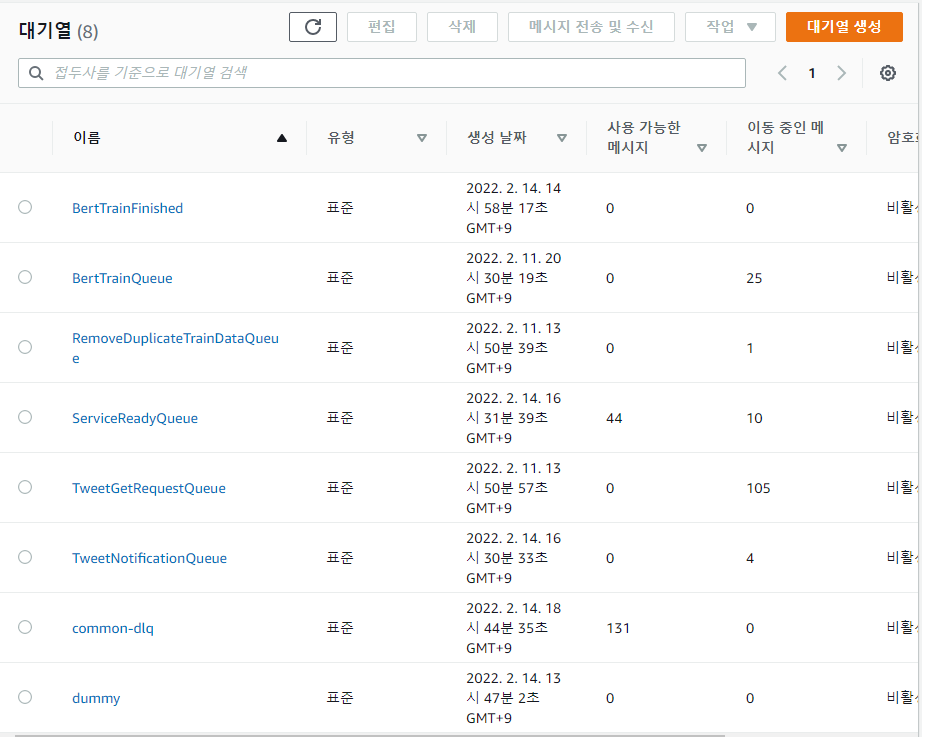
- キューベースのアーキテクチャを使ったことで、どこで詰まり、どこでエラーが起きているのかを素早く知ることができました。 SQS を使っていなかったらボトルネックを見つけるのにずっと時間がかかったでしょうが、キューベースのアーキテクチャのおかげで、どこで詰まっているのか簡単に見つけることができました。
- CloudWatch ログがすごくすごく便利で重要だと気づきました。 モニタリングシステムまで構築してリリースしようと思っていましたが、とりあえず一度出してみて反応が良ければさらに開発しよう(?)というナイーブな心持ちで、まずローンチしました。 しかしやはり問題が起き、開発時に習慣のように仕込んでおいた状態変化や Exception の出力などがエラー処理に大いに役立ちました。 AWS を使わなくても、ログをきちんと出して、ログの読み方を覚えておきましょう……。

- DLQ の設定は必ずやりましょう。 Poller(サービス処理者)が N 回以上処理しても Exception などで処理できなかったメッセージは、DLQ(Dead Letter Queue)という場所に集めておくことができます。DLQ を活用すれば、後で DLQ リドライブという機能で未処理のメッセージを元のキューに戻すことができます。 つまり、何らかの理由でエラーが発生して処理できなかったリクエストがあれば、それは DLQ に行き、後で DLQ リドライブを使って中断点から再処理できます!
ともあれ……かなり大変でしたが、なんとかかんとか乗り越えられたようで何よりです!
もし私が誤解している部分や改善できる部分があれば、いくらでもご意見をお寄せください!長文を読んでくださって本当にありがとうございました!
Comments