
Note: I’m based in Korea, so some context here is Korea-specific.
Lately, I’ve picked up a hobby of reading papers when I’m bored. Among them, I came across an interesting paper on arxiv, so I thought I’d organize and share it.
The paper is titled ChatGPT is a Knowledgeable but Inexperienced Solver: An Investigation of Commonsense Problem in Large Language Models (Arxiv Link
).
The topic is: Can large language models (ChatGPT) solve commonsense problems well? It’s a pretty interesting topic, so I’ll share what I’ve read while studying it myself.
I’ve never read papers before, and my undergraduate memories are fuzzy, so I want to mention upfront that I might be wrong! (Please let me know if I am, hehe.)
1. Summary
The paper raises the following questions:
- Can GPT effectively answer commonsense questions?
- Does GPT know commonsense well?
- Can GPT properly distinguish between commonsense that is necessary to answer a particular question and commonsense that isn’t?
- Can GPT effectively use given commonsense to answer questions?
And the brief answers are as follows:
- It can answer effectively, but it doesn’t answer well in specific areas related to social norms, causality, and time.
- It knows most commonsense well.
- It cannot properly distinguish between commonsense closely related (necessary) to answering a question and commonsense that isn’t.
- Even when additional commonsense is provided in context, it doesn’t use it well.
2. Categorization of Commonsense
The researchers classified commonsense into 8 categories. They are as follows:
1. General commonsense (widely shared common knowledge)
- The sun rises in the east
2. Physical commonsense (knowledge about the physical world)
- A glass cup breaks when dropped. Water flows downward.
3. Social commonsense (knowledge about social norms)
- When you receive help, you should say “thank you.”
4. Science commonsense (principles/knowledge of scientific concepts)
- Gravity pulls all objects toward the center of the Earth.
5. Event (causal) commonsense (knowledge about cause-effect and order)
- Knock over a water cup -> water spills
6. Numerical commonsense (commonsense related to numbers)
- A person has 2 hands and 10 fingers
7. Prototypical commonsense (knowledge about concepts)
- A swallow is a kind of bird and has wings
8. Temporal commonsense
- Traveling abroad takes longer than going for a walk.
And the researchers prepared 11 datasets related to commonsense for each category.
From left to right: dataset name / category / example question.
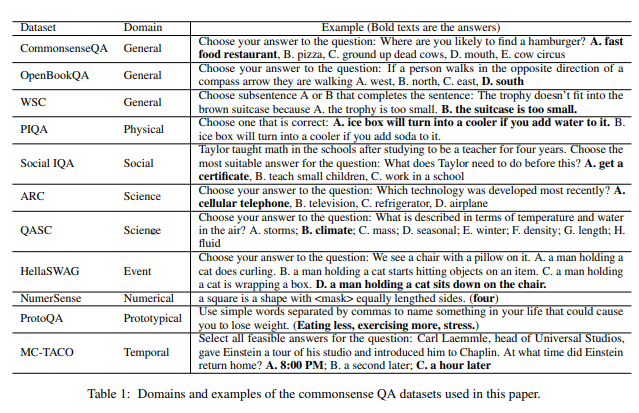
3. Can ChatGPT Effectively Answer Commonsense Questions?
The researchers picked 100 problems per dataset and asked GPT3, GPT3.5, and ChatGPT models.
Below are the correct-answer ratios of GPT3, GPT3.5, and ChatGPT for each question.
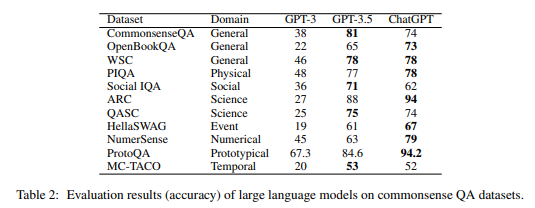
The notable points are as follows:
- Overall, it answers well.
- The Science domain shows the highest accuracy at about 94%.
- Accuracy for Social, Event (causal), and Temporal questions is low (under 70%).
- Overall, the tuned ChatGPT model has higher accuracy than GPT 3.5.
- For some questions, GPT 3.5 appears to have higher accuracy, but this is closer to an illusion caused by ChatGPT answering “I cannot determine the answer with the given data alone.”
4. Can ChatGPT Properly Distinguish Between Necessary and Unnecessary Commonsense for Answering a Question?
The researchers picked another 20 questions from each dataset.
Then, they asked GPT “what knowledge is needed to answer this question,” and based on human answers, computed Precision, Recall, and F1 Score.

Precision? Recall? Since difficult terms come up, let me organize them once before going in.
Precision: the accuracy of GPT’s answers
- What percentage of GPT’s answers are correct?
- For example, if 3 out of 5 answers are correct and 2 are wrong, Precision is 60%.
Recall: the number of correct answers GPT found out of all correct answers
- Out of the answers humans predicted to be correct, how many did GPT find?
- For example, if there are 5 predicted correct answers, and out of GPT’s 10 answers, 4 are correct and 6 are wrong, Recall is 80% (4/5).
- When calculating Recall, the wrong answers don’t matter!
F1 Score: the harmonic mean of Precision and Recall
- If you only use Precision as a metric: just answer the single highest-probability answer.
- If you only use Recall as a metric: write 10,000 answers and some will be right by chance.
- But what we want is an AI model that gives “accurate answers” “in sufficient quantity.”
- So if we take the harmonic mean of Precision and Recall, we get a metric similar to “accuracy”!
- In other words, high F1 Score == it answered well!
I went over difficult things! In conclusion, the following results were obtained:
- GPT has low Precision but high Recall.
- Across the entire dataset, Precision is 55.88%, but Recall is 84.42%.
- In other words, it provides almost all the knowledge needed to solve the question, but the precision isn’t high.
- GPT performs relatively well in the science field (F1 74-76%), but performs especially poorly in the social norms and temporal fields (F1 under 50%).
5. Is ChatGPT Knowledgeable About Commonsense?
The researchers manually created question prompts based on the necessary knowledge generated in section 3. Then, they manually evaluated whether the answers GPT generated were correct or incorrect.

The above question is an example of an incorrect answer generated by ChatGPT.
GPT said blowing into a trash bag and tying it with a rubber band may create a cushion-like surface, but it is unlikely to be durable or comfortable for prolonged use as an outdoor pillow, but the researchers reportedly treated this as incorrect because making a pillow out of a trash bag is a common practice.
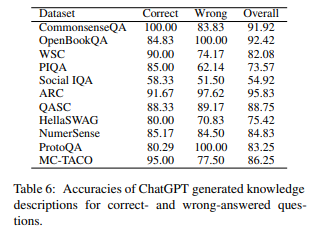
Based on the results table above, the researchers obtained the following results:
- GPT is knowledgeable and knows most of the commonsense needed to answer questions.
- It shows an average accuracy of 82.66% across the entire dataset.
- It shows an accuracy of over 70% on most datasets.
- However, it shows low performance of 54.92% in the social norms area.
- However, GPT’s answers contain misleading or overgeneralized, unnecessary knowledge.
- 26.25% of all answers contain low-relevance and misleading information.
- About 15% of explanations are overgeneralized and aren’t the specific information needed to answer the question.
6. Can ChatGPT Use Commonsense Added to the Conversation Context to Help Answer?
To check whether GPT can use commonsense from the context to answer, the researchers had GPT infer the commonsense needed to answer a question (as in section 4) and then answer the same question again, evaluating whether the answer changed.

The example above shows a case where a previously incorrect answer doesn’t change even after generating an additional explanation.
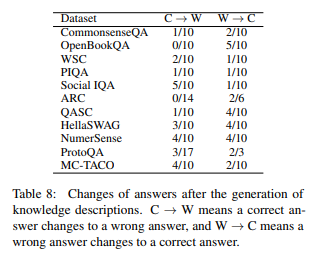
Based on the results table above, the researchers obtained the following results:
- Simply adding GPT-generated commonsense explanations to the conversation context doesn’t allow GPT to use them in answers efficiently.
- When explanations are added to context, there are both cases where correct answers turn into wrong ones (C->W) and where wrong answers turn into correct ones (W->C).
- For the Social IQA dataset, more cases (5) had correct answers turn into wrong ones because the added context commonsense was incorrect than the cases (1) where wrong answers turned into correct ones.
- The researchers presume that since knowledge has already been generated in the model, simply generating additional information doesn’t have much effect.
Even more, even when “user-provided correct commonsense” rather than “GPT-generated commonsense” was added to the conversation context, the accuracy did not reach 100%.
- Based on the human-annotated CoS-E and ECQA datasets, the correct answer (Golden Knowledge) was added to the conversation context.
- For CoS-E, wrong->correct increased by 4.
- For ECQA, wrong->correct increased by 8 and correct->wrong increased by 1.
- The researchers infer that GPT lacks the ability to use complex reasoning (e.g., negation reasoning).
- Example of negation reasoning
- Q: A basketball has a hole in it but its shape remains. Which is wrong?
- A: It has a hole, B: It’s popular in America, C: It’s full of air
- The CoS-E dataset explained “air cannot stay in an object with a hole,” but GPT still predicted A.
- Example of negation reasoning
// TODO: Write more…
Comments